I wrote a blog post a year or so ago about ESXi and storage queues which has received a lot of wonderful feedback (thank you!!) and I eventually turned it into a VMworld session and other engagements:
So in the past year I have had quite a few discussions around this. And one part has always bothered me a bit.
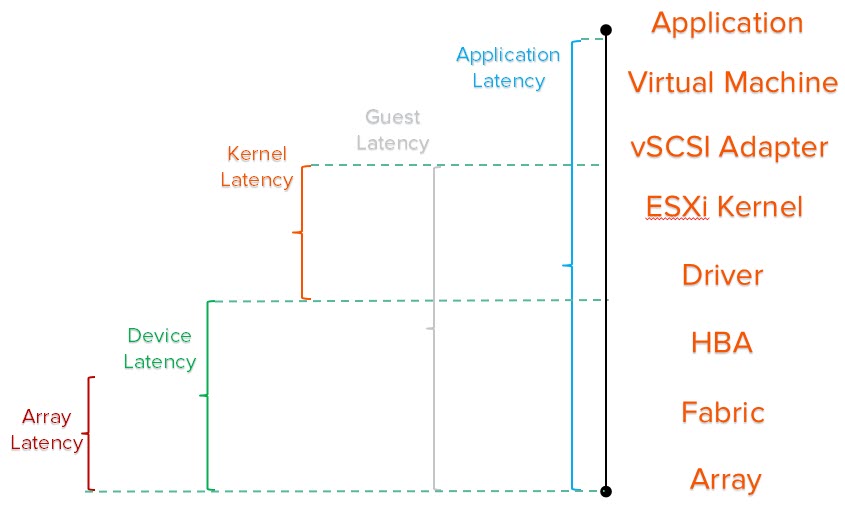
In ESXI, there are a variety of latency metrics:
- GAVG. Guest average. Sometimes called “VM observed latency”. This is the amount of time it takes for an I/O to be completed, after it leaves the VM. So through ESXi, through the SAN (or iSCSI network) and committed to the array and acknowledged back.
- KAVG. Kernel average. This is how long an I/O is spending in the ESXi kernel. If this is anything but zero, there is some kind of bottleneck (often a maxed out queue)
- DAVG. This is how long it takes for the I/O to be sent from host, through the SAN and to the array and acknowledged back.