Now that all of the prerequisites are complete, it is time to start creating protection groups and recovery plans.
This is part 3 of this series, the earlier parts were:

"Remember kids, the only difference between Science and screwing around is writing it down" -Alex Jason (made popular by Adam Savage)
Now that all of the prerequisites are complete, it is time to start creating protection groups and recovery plans.
This is part 3 of this series, the earlier parts were:
In my last post, I walked through configuring ActiveCluster and your VMware environment to prepare for use in Site Recovery Manager.
Site Recovery Manager and ActiveCluster Part I: Pre-SRM Configuration
In this post, I will walk through configuring Site Recovery Manager itself. There are a few pre-requisites at this point:
Continue reading “Site Recovery Manager and ActiveCluster Part II: Configuring SRM”
About four years ago, we (Pure Storage) released support for our asynchronous replication and Site Recovery Manager by releasing our storage replication adapter. In late 2017, we released our support for active-active synchronous replication called ActiveCluster.
Until SRM 6.1, SRM only supported active-passive replication, so a test failover or a failover would take a copy of the source VMFS (or RDM) on the target array and present it, rescan the ESXi environment, resignature the datastore(s) then register and power-on the VMs in accordance to the SRM recovery plan.
The downside to this of course is that the failover is disruptive–even if there was not actually a disaster that was the impetus for the failover. But this is the nature of active-passive replication.
In SRM 6.1, SRM introduced support for active-active replication. And because this type of replication is fundamentally different–SRM also changed how it behaved to take advantage of what active-active replication offers. Continue reading “Site Recovery Manager and ActiveCluster Part I: Pre-SRM Configuration”
vSphere 6.7 core storage “what’s new” series:
A while back I wrote a blog post about LUN ID addressing and ESXi, which you can find here:
ESXi and the Missing LUNs: 256 or Higher
In short, VMware only supported one mechanism of LUN ID addressing which is called “peripheral”. A different mechanism is generally encouraged by the SAM called “flat” especially for larger LUN IDs (like 256 and above). If a storage array used flat addressing, then ESXi would not see LUNs from that target. This is often why ESXi could not see LUN IDs greater than 255, as arrays would use flat addressing for LUN IDs that number or higher.
ESXi 6.7 adds support for flat addressing. Continue reading “What’s New in Core Storage in vSphere 6.7 Part VI: Flat LUN ID Addressing Support”
VVols have been gaining quite a bit of traction of late, which has been great to see. I truly believe it solves a lot of problems that were traditionally faced in VMware environments and infrastructures in general. With that being said, as things get adopted at scale, a few people inevitably run into some problems setting it up.
The main issues have revolved around the fact that VVols are presented and configured in a different way then VMFS, so when someone runs into an issue, they often do not know exactly where to start.
The issues usually come down to one of the following places:
One of the great benefits of vVols is that fact that virtual disks are just volumes on your array. So this means if you want to do some data management with your virtual disks, you just need to work directly on the volume that corresponds to it.
The question is what virtual disk corresponds to what volume on what array?
Well some of that question is very array dependent (are you using Pure Storage or something else). But the first steps are always the same. Let’s start there for the good of the order.
At the Pure//Accelerate conference this year, my colleague Barkz and I gave a session on data mobility–how the FlashArray enables you to put your data where you want it. The session video can be found here:
In short, the session was a collection of demos of moving data between virtual environments (Hyper-V and ESXi), between FlashArrays, and between on-premises and public using FlashArray features.
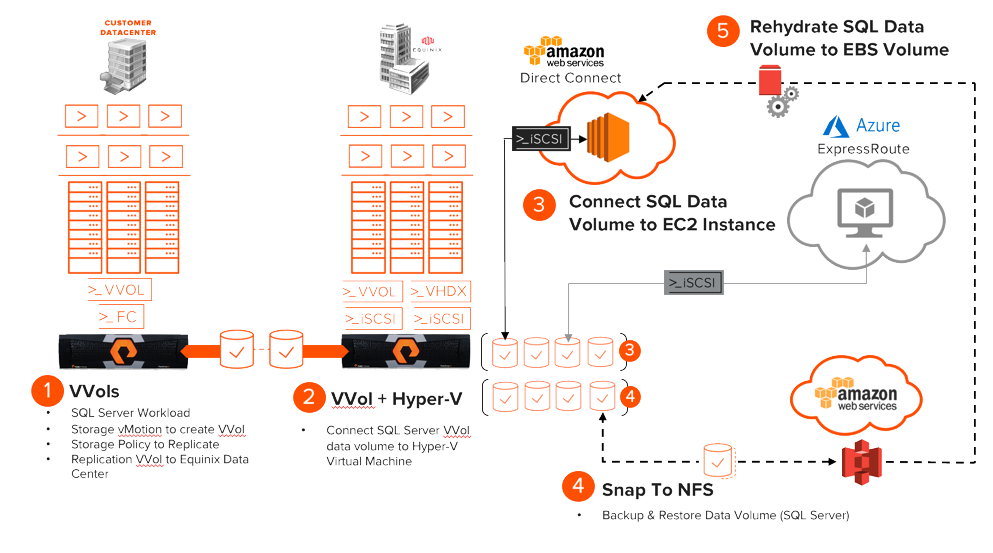
Continue reading “Data Mobility Demo Journey Part I: Virtual Volumes”
In Purity 5.1 there were a variety of new features introduced on the FlashArray like CloudSnap to NFS or volume throughput limits, but there were also a variety of internal enhancements. I’d like to start this series with one of them.
VAAI (VMware API for Array Integration) includes a variety of offloads that allow the underlying array to do certain storage-related tasks better (either faster, more efficiently, etc.) than ESXi can do them. One of these offloads is called Block Zero, which leverages the SCSI command called WRITE SAME. WRITE SAME is basically a SCSI operation that tells the storage to write a certain pattern, in this case zeros. So instead of ESXi issuing possibly terabytes of zeros, ESXi just issues a few hundred or thousand small WRITE SAME I/Os and the array takes care of the zeroing. This greatly speeds up the process and also significantly reduces the impact on the SAN.
WRITE SAME is used in quite a few places, but the most commonly encountered scenarios are:
vSphere 6.7 core storage “what’s new” series:
VMware has continued to improve and refine automatic UNMAP in vSphere 6.7. In vSphere 6.5, VMFS-6 introduced automatic space reclamation, so that you no longer had to run UNMAP manually to reclaim space after virtual disks or VMs had been deleted.
vSphere 6.7 core storage “what’s new” series:
Another feature added in vSphere 6.7 is support for a guest being able to issue UNMAP to a virtual disk when presented through the NVMe controller.