We just released our latest version of our Storage Replication Adapter, version 4.0 for VMware Site Recovery Manager. There are a lot of enhancements in this release and improvements–if you are on 3.1 (or certainly earlier) I recommend an upgrade when you get a chance.
For all the need-to-know information (release notes, user guide, videos, download link, etc.) see here:
Hey there. My name is Cody and I am the Director of VMware Solutions Engineering at Pure Storage. How lovely.
The reason I introduce myself is because I want to introduce to you my team. My team is called, well, VMware Solutions Engineering. What does that mean? Well about a year ago, my team was moved from an umbrella team (Product and Solutions) into the larger engineering organization. At the time, we were called the VMware Solutions Team.
After some months, we renamed ourselves to VMware Solutions Engineering. Since moving into the engineering org, I started to get a lot of questions about what we actually did.
Though it was less about “I think you don’t do anything” it was more about “you are involved in a lot of random things, what is your actual task?”. A fair question. And thinking through this answer is why we renamed ourselves.
What is a Solution?
A fairly nebulous term. A solution is certainly an answer to a problem–I think we can agree on that. But in the context of technology usage, a solution is the answer to one question: “Why does your product matter?”
Building a feature or a product does not exist in a vacuum. A storage array is meaningless without data. An enterprise array is meaningless without important data.
So from a solutions perspective, we give reasons to our customers to use our product. We tell them why it is useful. For it to be useful, it must be useful to some other part of your infrastructure. If you add X on top of (under, alongside of, etc.) Y, it creates business value. Creates efficiency. Improves operations.
I relate this to building a car. To make that car successful, customers needs to know:
That the car exists (talk about it in the places the customers reside/pay attention to)
Where the car can go (with this car, where can I go).
How this car can get you there (how to use it)
In a VMware world, this is about a few things.
First, we have a storage array. We need to present about it at VMware conferences, user groups, webinars, etc. Make it known in that area. Yes, that is marketing (what isn’t?) but it is marketing with technical context. Which is the next part.
Our product integrates with the VMware Product, ESXi or Site Recovery Manager, or Tanzu. Knowing if you want that product, we have a solution (and a great one!) is certainly important.
The last part is how our storage integrates with those products. This is the part I want to focus on–as this is the “solution”. Many things go into making a solution successful (engineering, sales, marketing, customers, etc), but let’s focus on building the solution.
Creating a Solution
I will first start with the assumption that I know the specific question I am trying to answer. This usually boils down to the form of “how does partner product (feature|tool|API|) X work with my product (feature|tool|API|) Y.
My thinking around building a solution is that the two products should work right out of the box. Meaning that once I cable them, or connect them, or authenticate them, it should just work. I shouldn’t have to configure them, I shouldn’t have to know something specific about it to get it to work. And by work, I mean work well. The default behavior should not be some test configuration, but the best configuration. Doing this is a non-trivial amount of work–and not work we should push to our customers whenever possible.
So what this essentially means is that we are creating best practices. The best practice ideally should be: turn it on. Authenticate it. Connect it. Not tune this, change this, turn this off, increase that.
So how do you achieve this? First ask: Does X and Y work together optimally out of the box? If the answer is yes. Your work is done. Most often, the answer is no.
Take care of yourself first
If no, the right step is not to jump on 1,000 phone calls and tells every customer how to tweak and configure. The right step is to have one call with engineering. What can we do to make our product behave correctly? How can we improve it to ensure that when these two things are connected, they work together, correctly, and immediately. Do we need a feature? Do we need to change a feature? Do we need to make our product smarter?
If that is possible–that should be the goal. If that is not possible, or the timelines are too far, or that alone will not fix it, we must take the next step.
“A rising tide lifts all boats”
The next step is to work with the engineering team of your partner product. Can you work with them to make a new default behavior that understands your product and behaves accordingly? Can they change their product to allow all products (similar to yours) to tell it how to behave? Can they make their product smarter?
This, sometimes is the ideal choice–often even before making your own product better-the creation of an industry option, creates buy-in, which creates investment. Some times niche, one-off vendor specific solutions are hard to support, can become irrelevant if the partner makes a single small change, and can lose value quickly. So when looking at changing your product, or changing the partner product, or both, it is important to think long term. Does this need an ecosystem?
Plug it in, plug it in
If neither of those are possible or it only gets you so far, it is time to build an integration. Something separate from the two pieces, but joins them together. This is what I have told my team-this is how we can scale out our efforts. This is how we can make more people happy, without doing more work, and without adding people.
Instead of 1,000 customer calls, we have 1 (or a dozen) calls with a few engineers. This is how, these two things, could work together. Let’s build a plugin, a module, a pack, a whatever, that can integrate these things in the right way. This will let product X work with our product Y, or at least allow the user of product X to be able to use our product Y from within product X.
This is sometimes the best option. It might be the only option. A benefit of the plugin, is that you can often move faster–you do not have nearly as many dependencies. But with more moving parts, more things can break–and things can break that are not within your control. Things can change that make your plugin (or parts of it) useless, broken, or even flat-out harmful.
The written word.
I don’t want to really say this is the ripcord. You should ALWAYS write it down. This is where all paths lead. I have told my team many times, I don’t care too much about what you are doing on a given day, as long as you are writing it down for others. The more information we share, the more we can grow into other areas. Keeping information to yourself is counter-productive. Yes it makes you useful for a time, but you keep getting pulled into things, because no one else knows. Then eventually that information doesn’t matter anymore and you never had the time to learn new things and you quickly go from crucial to useless.
So whether you built something into your product, or you worked with the partner to enhance theirs, or you created an ecosystem option, or built a plug-in, or just figured out how to get them to work, you should write it down. Explain the what, the why, and the how.
If the best practice is to just connect the two, say it. If it is to enable this feature, install this plugin, deploy this framework, or change this setting, say it.
Ideally somewhere up top of this solution solving hierarchy is where this was resolved, the more that needs to be done and changed by the end user, the more that needs to be explained and understood. If they work out of the box, the details are interesting, but not necessary. I see best practice settings as “solutions bugs”. Things to be automated, removed, or resolved.
Is some of the above hand-wavy? Yeah. But generally, this is my process to build a solution.
Identifying what Solution to do
So it is my jobs’ team to figure out what solutions we need. This is sometimes the toughest part. What needs to be done, and in what order is often much harder than how it gets done. We get these requirements in a few ways.
Customer is asking for it.
An obvious one for sure. But can be the trickiest one. Just because this customer needs it, do others? Is it worth spending the time on? The ugly tradeoff on ROI still can be there, and saying no can be an excruciating choice. But often, the solution can just fall further down the ideal solution totem–document how, don’t build.
But sometimes, is the customer asking the wrong question? Can this be resolved in a different way that makes the request irrelevant? Always think about this question. Over-engineering, though, can be a trap. Also–is something coming soon that might make this irrelevant?
The industry is focusing on it
Conference talks, marketing, announcements. If this level of attention is being paid, it is worth thinking about. Is it fluff? Or could it be something.
Users are complaining about it
Herein lies opportunity. Pay attention to Twitter, to sub-reddits, to message boards. If people are struggling it usually means 1) it is worthwhile 2) there is a lot of room for improvement
Can a solution with our product do something different with it? Or make it better? Simpler? Faster?
Gut Feel
There is a certain amount that is just instinct. Users are dealing with some other problem now, but their next problem will be this. If we invest now, when they start seeing it–we will be the clear and first choice. Playing the long game a bit, but can pay off big time.
Conclusion
So why Solutions Engineering? Well we might not necessarily write code (though often we do in the form of scripts and tools), but this involves a lot of engineering. One of the reasons I love working in solutions is that you get to do a bit of everything. Engineering. Writing. Testing. Designing. Presenting. Listening. Recording.
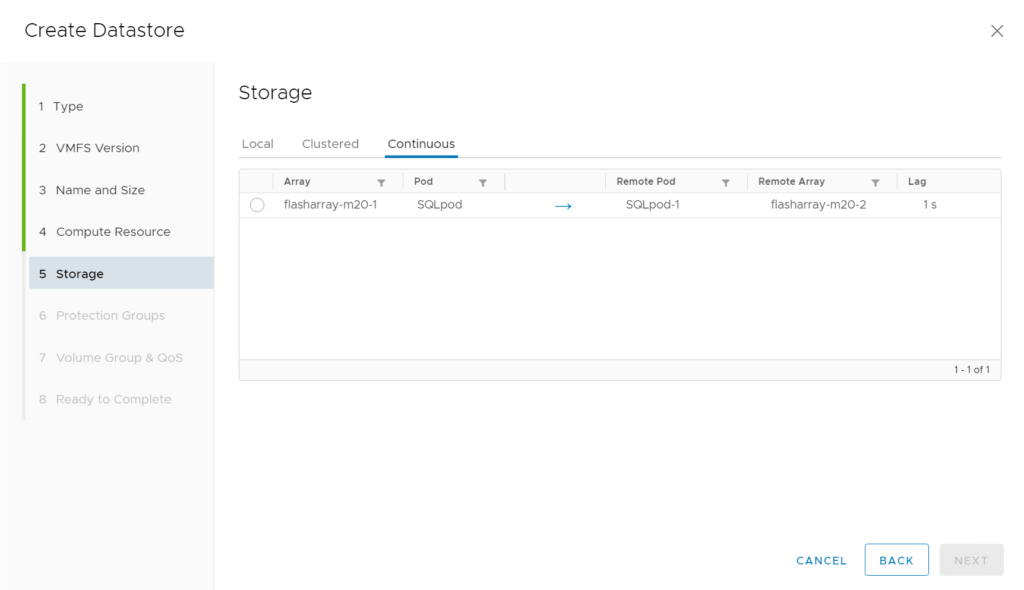
Datastores can now be provisioned to ActiveDR pods via the plugin:
There is a new tab “Continuous” which is where you will find ActiveDR-enabled pods. The fields show the source pod (where the volume would go), the target pod (where the volume will be replicated to), the source and target arrays (which currently own those pods), the replication direction, and the “lag”. The lag is how far behind the target pod is from the source pod.
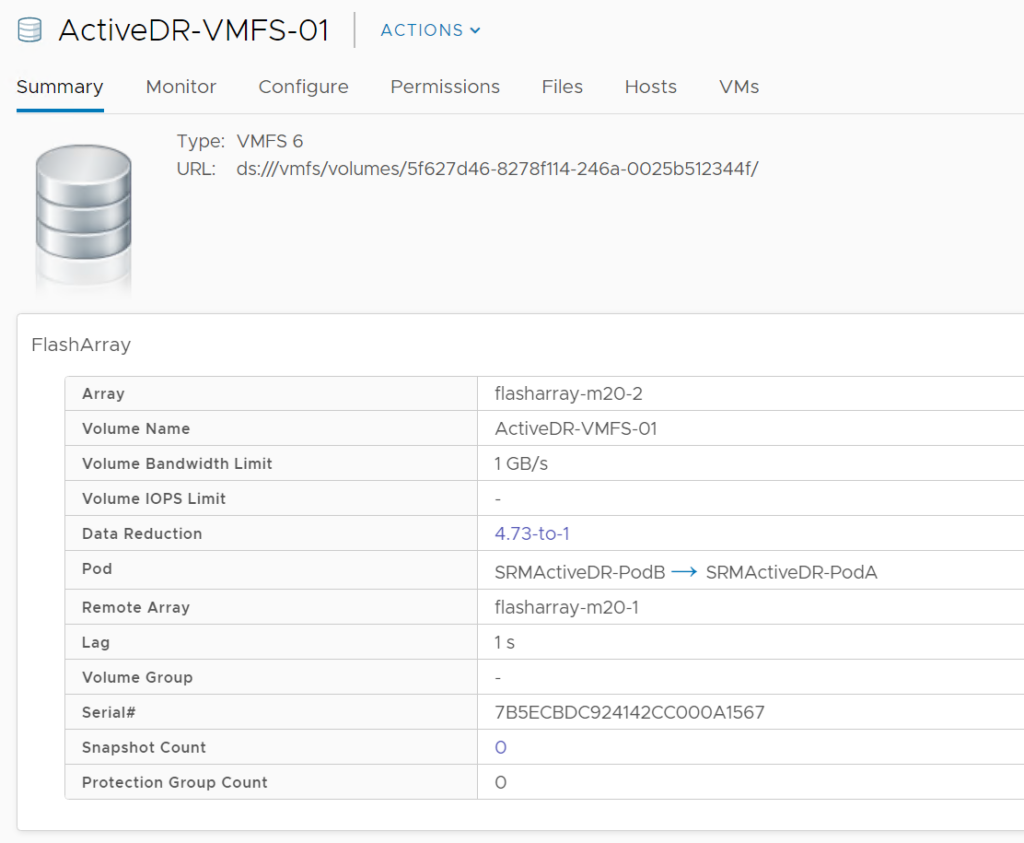
When you click on a datastore, you will see a few more pieces of information in the FlashArray summary panel:
This will show the ActiveDR information if the volume of course is in an enabled ActiveDR pair. The plugin also supports all of the usual features with ActiveDR datastores: resize, rename, QoS, snapshot, refresh from snapshot, copy from snapshot.
Demo of provisioning and ActiveDR datastore:
vVol Snapshots
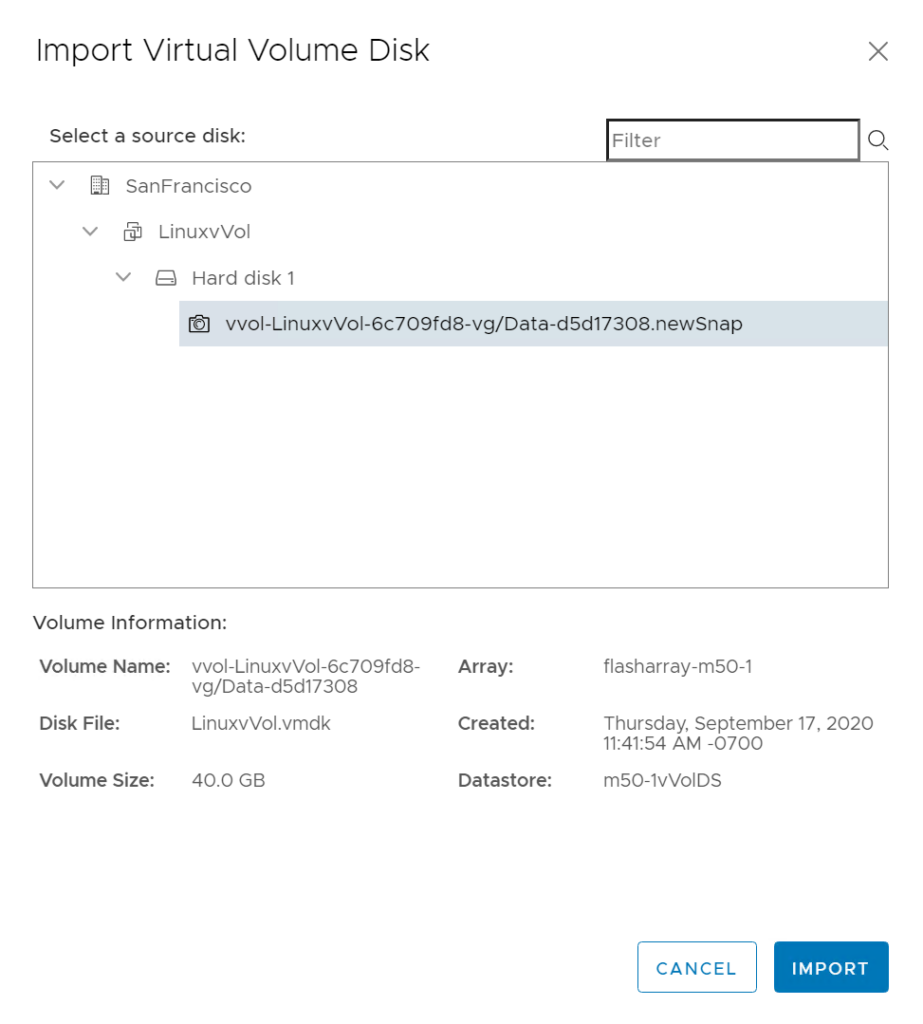
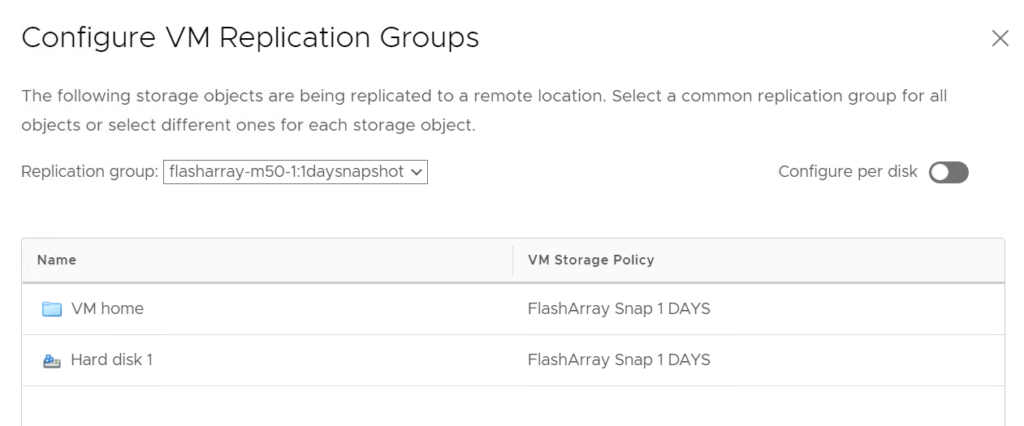
You can create a snapshot of a VM using the standard VMware snapshot tool, but that snapshots every single virtual disk–which you may not want/need. We used to have the ability in the plugin to create a one-off snapshot of a vVol, but removed it due to some early issues that have since been resolved. This feature has been reintroduced:
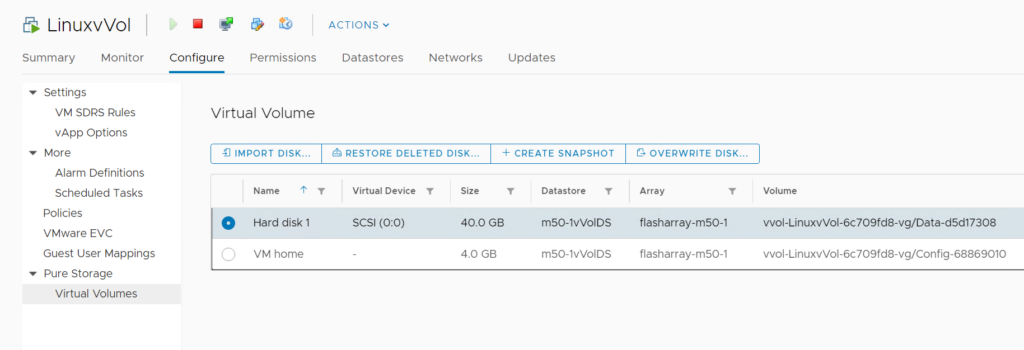
Now you can click on a vVol-type VM and navigate to the Configure tab and click on Pure Storage – > Virtual Volumes.
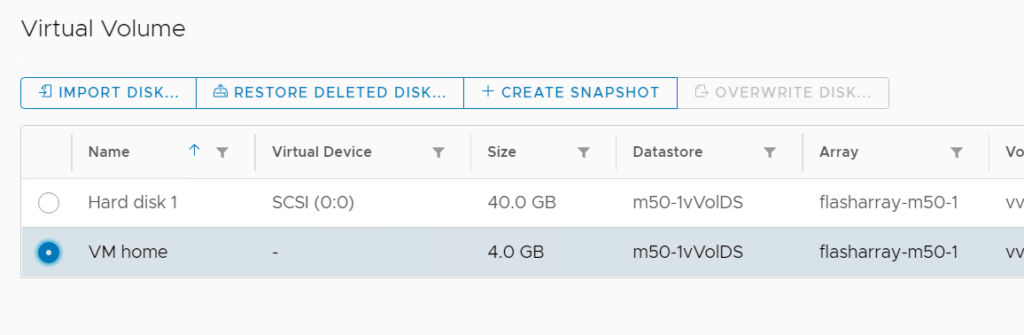
You can select a single vVol disk and click Create Snapshot.
This will create a new single snapshot of the volume that is that vVol. You can then restore from it, or copy from it with the other tools.
You can also do this with the home directory (config) vVol. Why would you want to snapshot this? Well because protects your virtual machine configuration. The pointer files, the VMX file, snapshot hierarchies, logs, etc. If you accidentally make a change to the VMX file that breaks your VM (or you made a lot and don’t know what you did) the restore can restore the config without having to restore the entire VM.
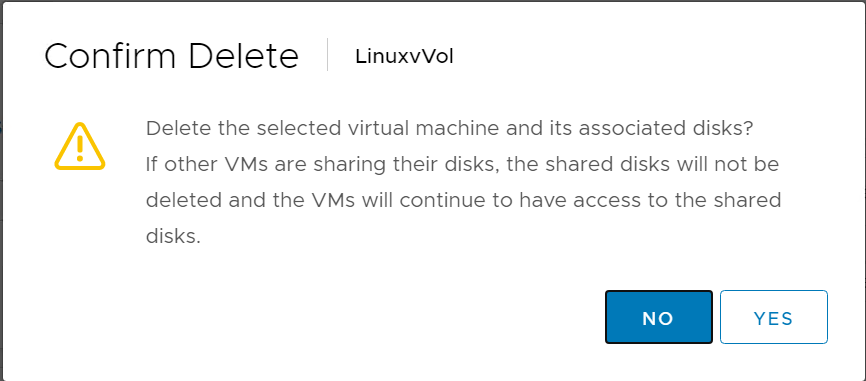
The other reason, is “undelete” protection. When you delete a VM, ESXi first deletes all of the files from the config vVol, then it tells the array to delete the volumes. When we delete volumes, we put the volumes in the destroyed volumes folder, then they get permanently deleted in 24 hours (by default) or manually by an admin (unless safemode is turned on and then manual eradication is not possible).
The problem here, is that if you delete a VM, we can restore the config volume itself, but VMware wiped the data from it. So it is blank. VMware does not wipe the data from the virtual disks, so those can be “undeleted” and the original data is still there. So to fully restore an undeleted VM, we need a snapshot of the config vVol. This will restore all of the files.
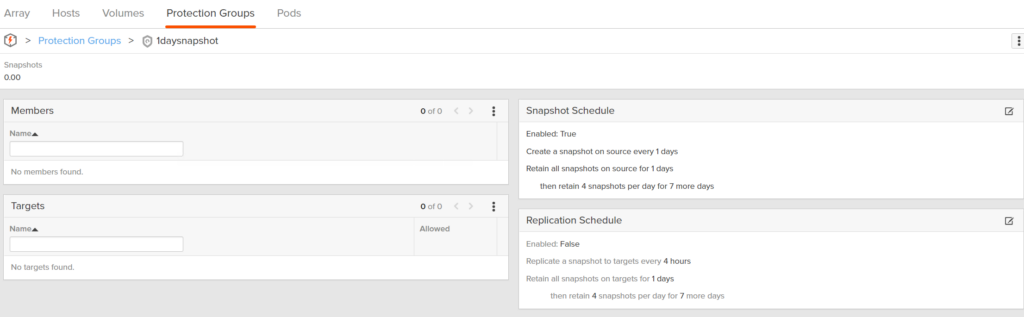
The ideal option here, is to assign a snapshot storage policy to the home vVol (or even more ideally all of the vVols) to have the array snapshot on a schedule:
So to do this, create a 1 hour snapshot protection group on the FlashArray:
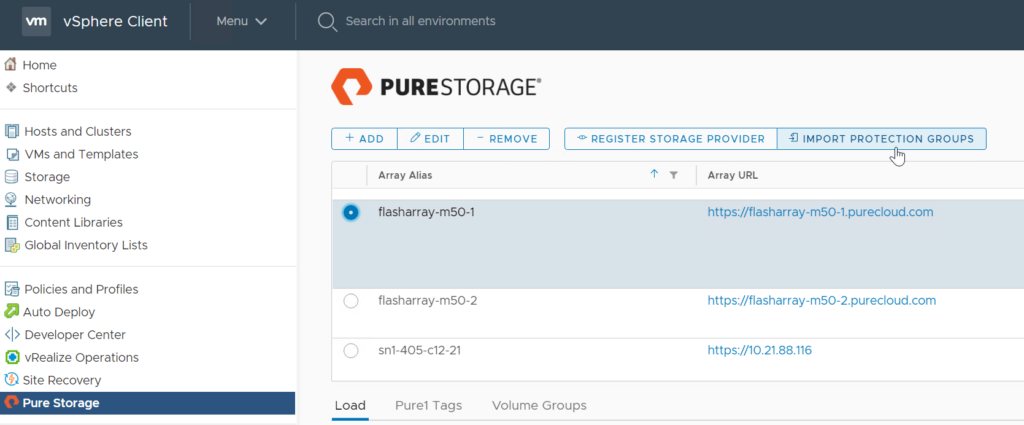
Import the protection group into vSphere as an SPBM policy:
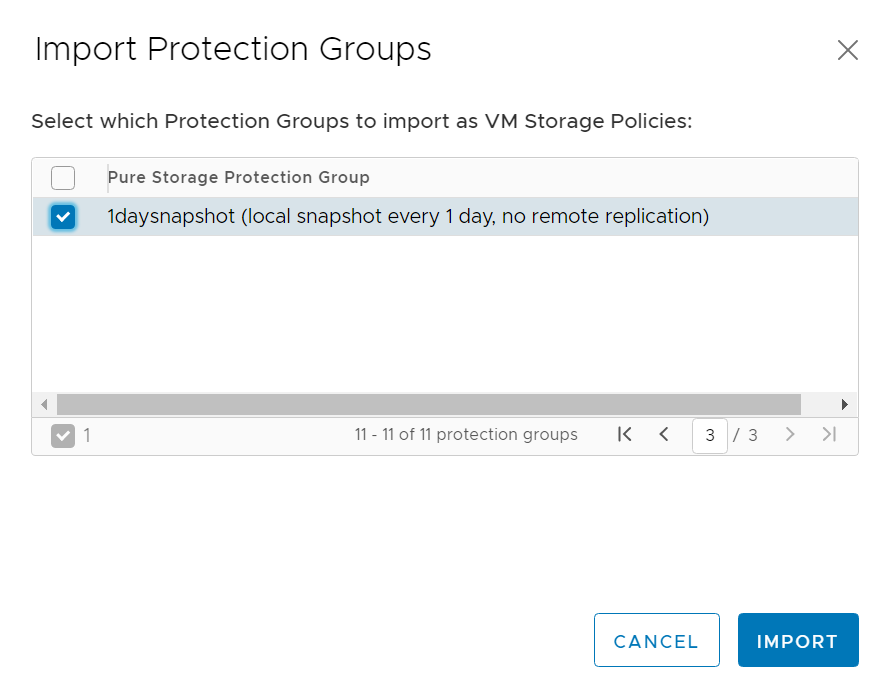
Select and import:
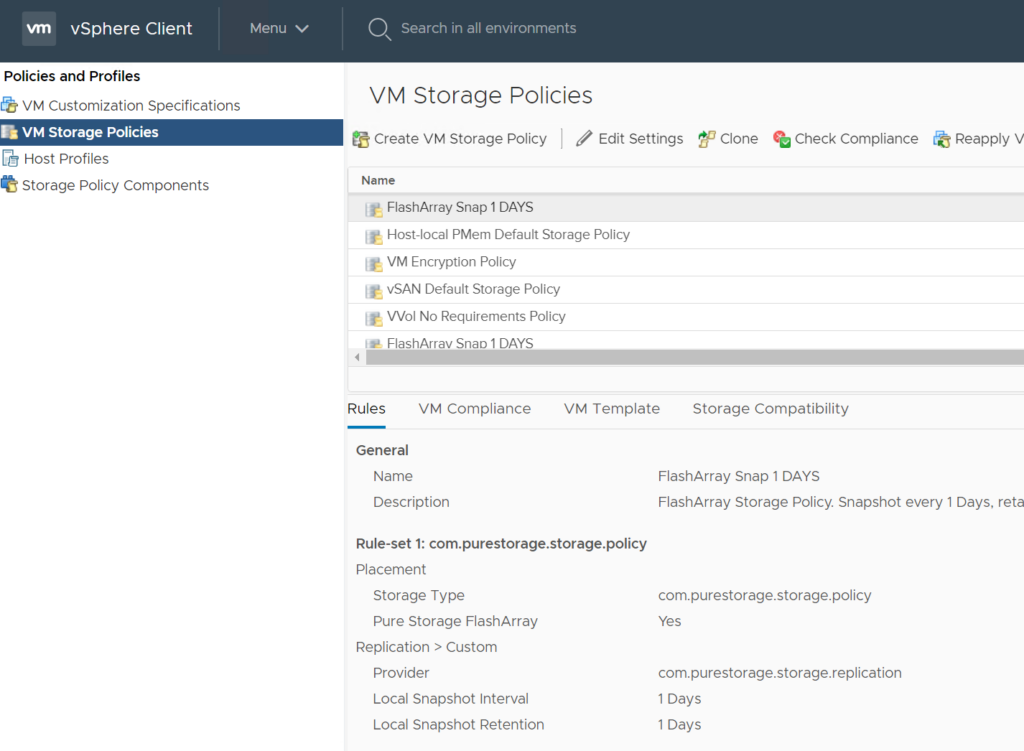
And it is now a policy:
Then assign the policy and the group to the VM (or just the VM home to protect the config).
If you don’t need frequent snapshots of the config vVol and just one will do (or whenever you want), this is what we added. You can select the VM home and click the Create Snapshot button:
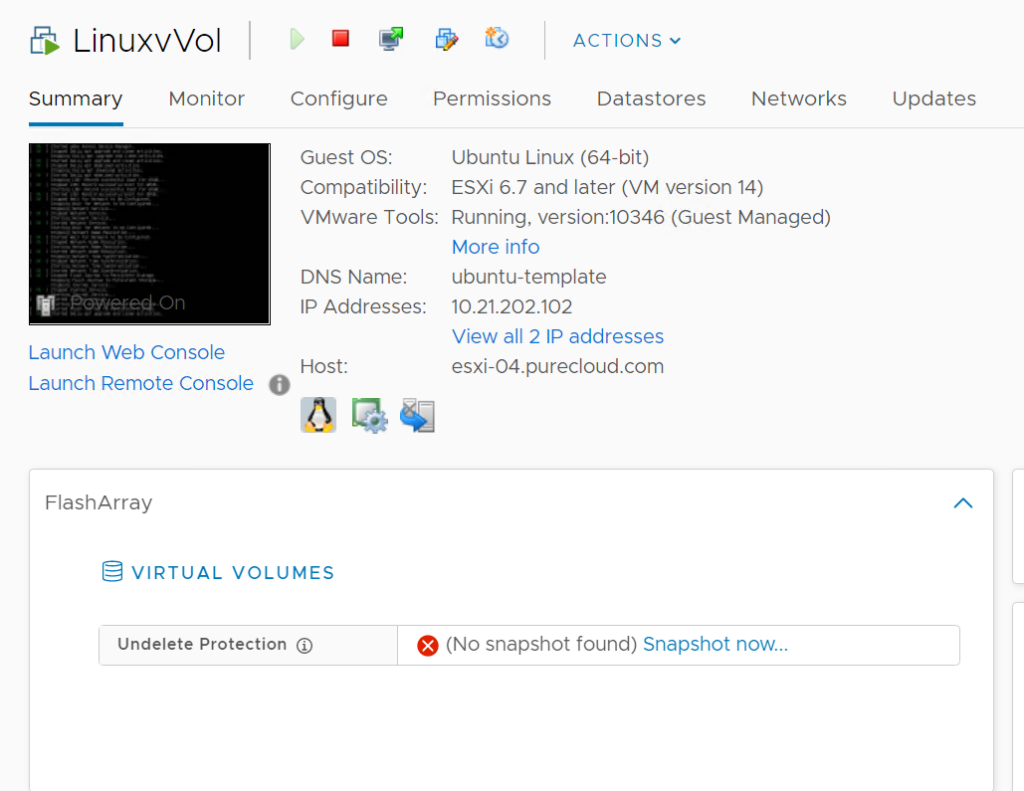
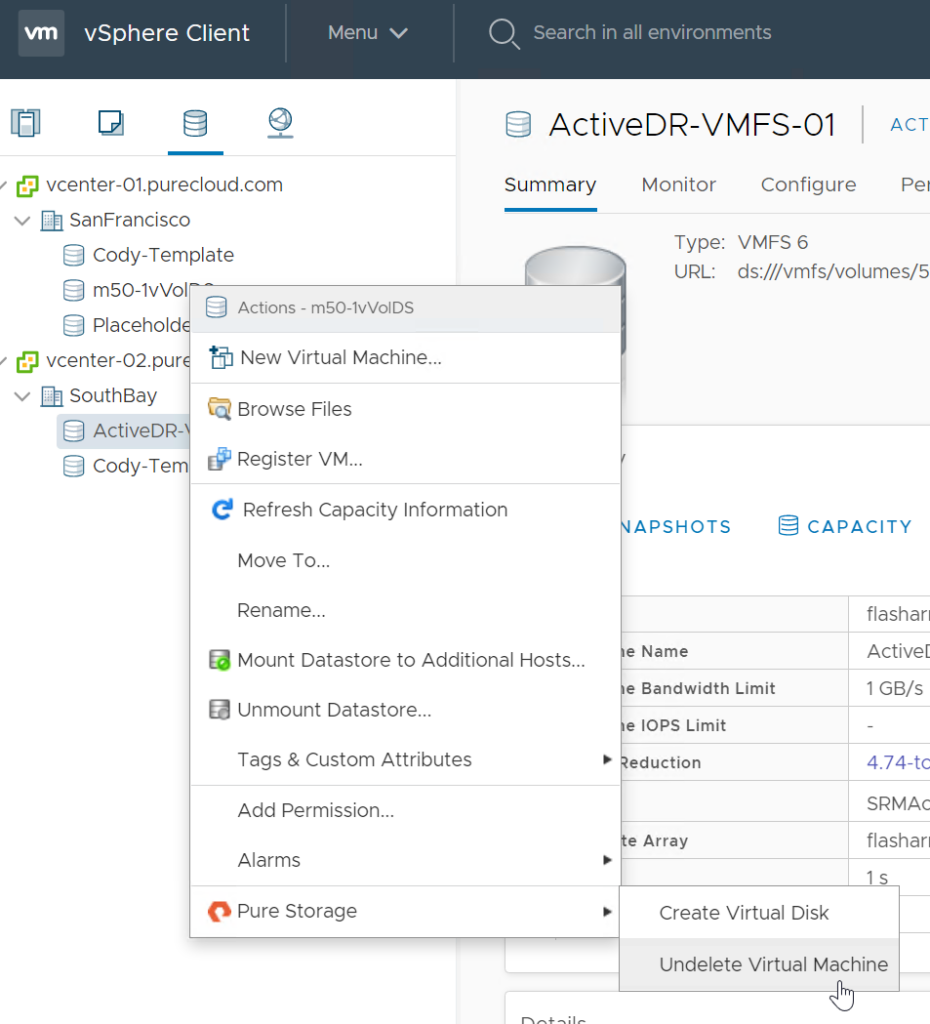
Alternatively we have another place to do this. If you click on the VM summary tab and look at the FlashArray panel, there is an Undelete Protection box. If we do not see any snapshots for the config vVol, we will show a warning like below:
What this means, is that we cannot fully restore this VM if it is accidentally deleted. The data, yes. But the VM configuration, no. You can create a snapshot from here too, by clicking Snapshot now…
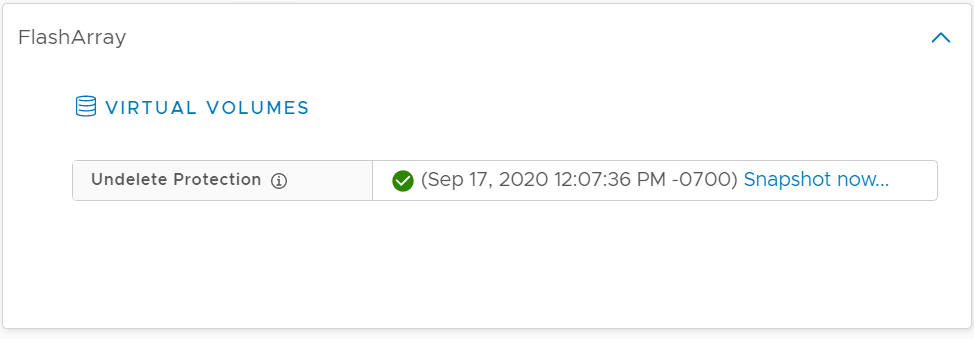
If it is protected, we will show the timestamp of the latest discovered snapshot:
So if you delete it:
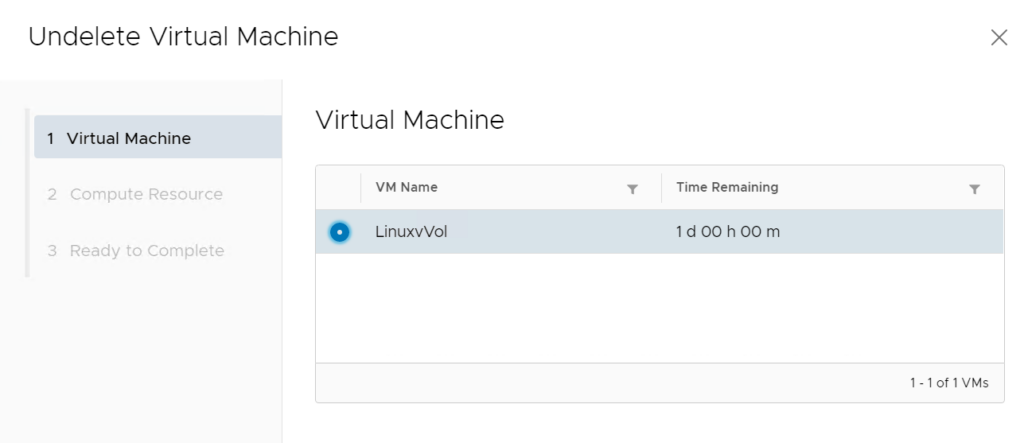
You can restore via the plugin easily:
If the VM configuration is changing a lot–you probably want to protect via schedule. If the VM does not change a lot, then one off snapshots will work fine.
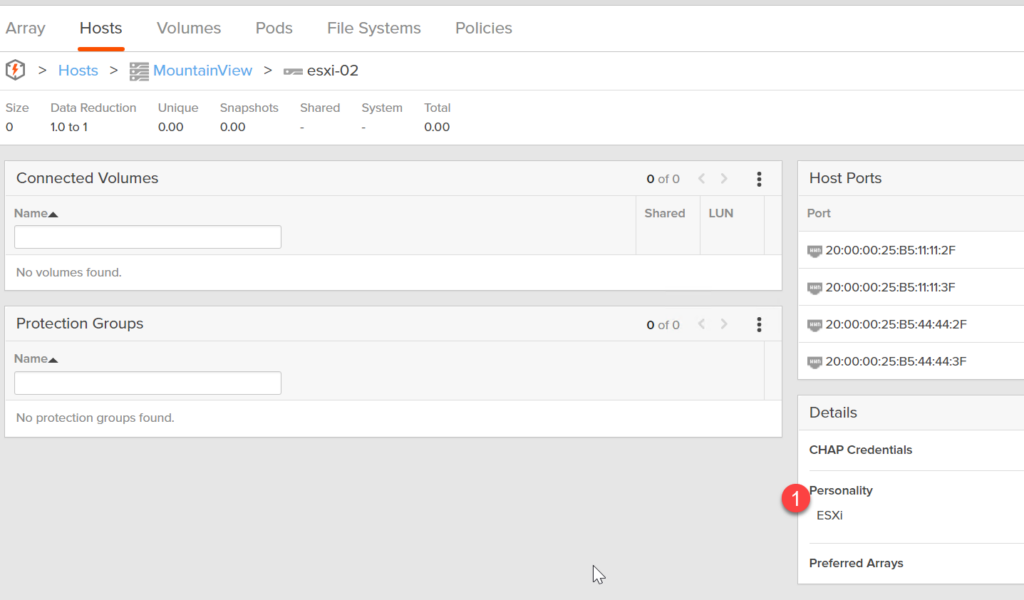
ESXi Host Personality
Also, we now set the ESXi host personality when creating new clusters:
This is important for some ActiveDR and ActiveCluster scenarios, so it is our best practice by default.
While the title of this post does sound like a halfway decent Harry Potter novel, this is far more nefarious. Pure Storage, like many other vendors have a best practice around lowering the Disk.DiskMaxIOSize setting on ESXi hosts when using UEFI boot for your Windows VMs. Why? Well:
Yes not having it set in a few situations would cause BSOD. First off, why?
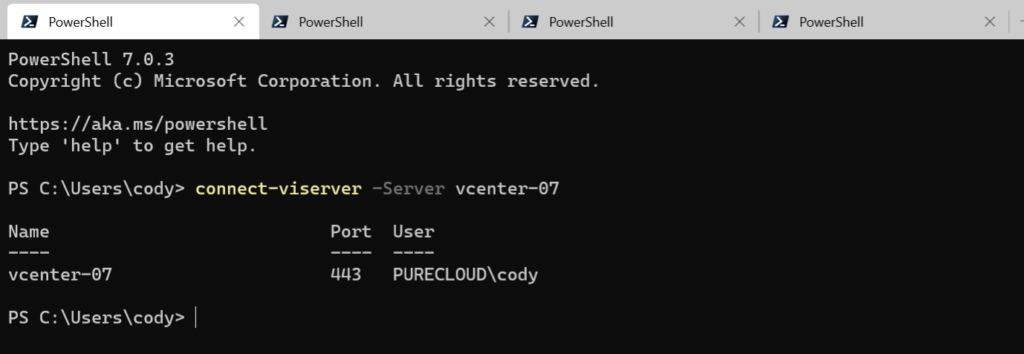
I often will connect to multiple vCenters, but even more frequently will have multiple vCenters connected but in separate sessions or tabs:
Four tabs, four vCenters. And I never clicked on the one I meant to be cause they were all called PowerShell. In a fairly recent release, Windows terminal added the option to rename the tabs:
Ah yes. Tagging. The one above them all. A simple feature, but nonetheless powerful.
We have actually had tagging in Purity for quite some time. But it was hidden–we initially used it only for Virtual Volume metadata. Though there are a ton of use cases for tags beyond vVols–use cases I know customers need, and use cases that I need.
So in Purity 6.0 we added tagging–the ability to assign key value tags to a volume or a snapshot. As of Purity 6.0, these tags are available in the CLI or the REST API–GUI support is upcoming. For this post I will walk through using the CLI to demonstrate the tags, stay tuned for information on using the REST and specific scripting tools.
Purity 6.0 ships with a new REST version 2.2. 2.2 includes the endpoints to manage ActiveDR processes (demote/promote), tagging (more on that in a later post) and more.
REST 2.x is a new major release of our REST API that changes the underlying structure of the API, the endpoints, authentication, queries, etc. Our current PowerShell SDK uses REST 1.x (which is changing) but for folks who might want to write their own PowerShell against REST, or starting using it now–here is some help.
I wanted to go into more detail on ActiveDR (and more) in a “What’s New” series. One of the flagship features of the Purity 6.0 release is what we call ActiveDR. ActiveDR is a continuous replication feature–meaning it sends the new data over to the secondary array as quickly as it can–it does not wait for an interval to replicate.
For the TL;DR, here is a video tech preview demo of the upcoming SRM integration as well as setup of ActiveDR itself
But ActiveDR is much more than just data replication is protects your storage environment. Let me explain what that means.