
Hello- my name is Nelson Elam and I’m a Solutions Engineer at Pure Storage. I am guest writing this blog for use on Cody’s website. I hope you find it helpful!
With the introduction of Purity 6.1, Pure now supports NVMe-oF via Fibre Channel, otherwise known as NVMe/FC. For VMware configurations with multipathing, there are some important considerations. Please note that these multipathing recommendations apply to both NVMe-RoCE and NVMe/FC.
The reason why changing multipathing is important and useful is multi-faceted, but mostly, it provides more reliable connections to your datastores (and the volumes backing them) when things aren’t behaving well, whether that be from a failed fabric connection point or a partially degraded fabric. For ESXi 6.7 U1+, VMware introduced latency-based round robin policy that can help in these situations.
Multipathing configuration is different with NVMe-oF vs SCSI FC/iSCSI. NVMe-oF devices no longer use the Native Multipathing Plugin (NMP) for multipathing configuration. For higher speed protocols, such as NVMe, the ESXi host will now use the High Performance Plugin (HPP) for path management and configuration.
To start with, we’ll focus on the CLI and then I’ll show you how to configure devices through the GUI.
From an ESXi host, you run this command to give you the list of claim rules configured currently:
esxcli storage core claimrule list
These behave similar to SATP rules in the sense that after you set them, you will either have to manually apply them to each previously configured NVMe-oF datastore or you will have to restart the host for them to apply to the changes; all new datastores after you have applied the rule will have the claim rule after you have applied it.
The two different classes here are “runtime” and “file”. file means that the configuration that you changed has been successfully saved and will be read upon a reboot or reload of the claim rules. Runtime means it is actively loaded into memory and will apply those rules to any new devices added after the rules were committed.
To apply the rule to an existing datastore without restarting the host, you’ll first need to get the EUI of the datastore. You’ll first run:
esxcli storage hpp device list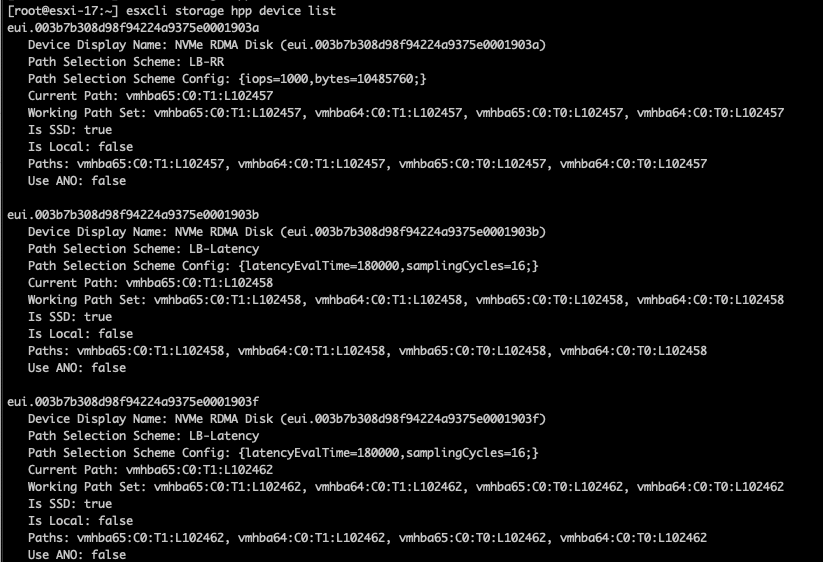
Let’s grab that first device here with the EUI of eui.003b7b308d98f94224a9375e0001903a. We can see this is currently configured to use LB-RR, which is what we are expect normally, Round Robin:
“LB-RR: [Default] Load Balance – Round Robin scheme chooses path in round robin manner based on IOPS and bytes count. –iops and/or –bytes options can be specified as input. This is the default path selection scheme for the device.”
If you want to see what all of the options are for path selection scheme (PSS), you can run “esxcli storage hpp device set” and you’ll get this output which goes over some other options you have here:

To change this device to the latency based path selection scheme, we’ll want to run this command:
esxcli storage hpp device set -d eui.003b7b308d98f94224a9375e0001903a -P LB-Latency -T 180000 -S 16- “-d eui.003b7b308d98f94224a9375e0001903a” is specifying our device.
- “-P LB-Latency” specifies the path selection scheme we want to use; latency based.
- “-T 180000” specifies our polling interval (in ms) for how often we check the latency of each path. This works out to 3 minutes.
- “-S 16” specifies how many IO will be sent down each path to figure out the latency.
Now that we have set the new path selection scheme, we can check it with:
esxcli storage hpp device list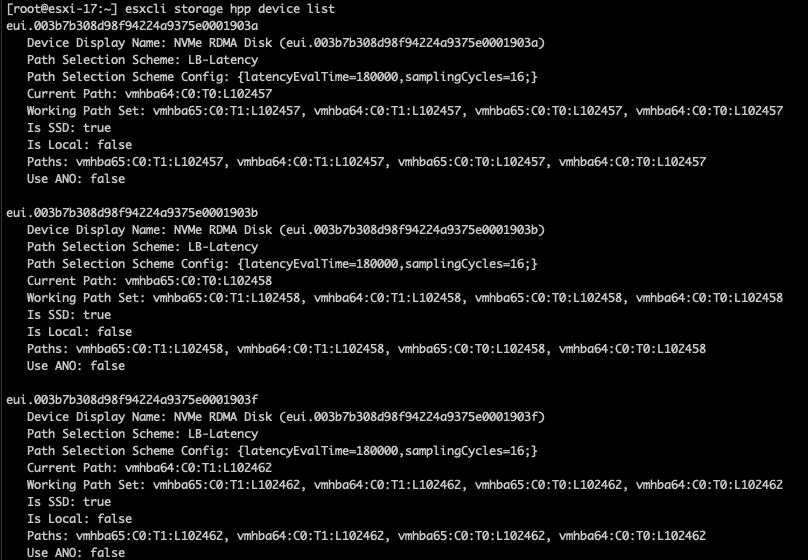
Now we can see that our first device has been changed to the parameters we set before.
For all future Pure NVMe-oF devices, we’ll want to apply the claim rule like below:
esxcli storage core claimrule add --rule 102 -t vendor -P HPP -V NVMe -M "Pure*" --config-string "pss=LB-Latency,latency-eval-time=180000"
Some notes on this:
- We are setting the vendor to “NVMe” and the model is “Pure*” to identify Pure devices.
- pss=LB-Latency means we are using the latency based path selection scheme, which prioritizes sending IO down paths with lower latency.
- latency-eval-time=180000 means that the host is evaluating latency on these paths every 180000 milliseconds (3 minutes) to figure out which path(s) to send IO down.
- The rule number is the order in which the ESXi host will try to apply that rule. It will start from 0 and go up in count from there trying to apply a rule that matches the newly added device. If it can’t find a rule, it will apply the last rule in the list to that device.
After our claimrule has been added, to apply the file configuration to a running one, we’ll want to run:
esxcli storage core claimrule load
Now, for any new Pure NVMe-oF datastores, you will have the path selection scheme set to latency based and the latency evaluation time set to 3 minutes.
To see what multipathing you have set up by datastore and to make changes to it, you can go to the GUI and check.
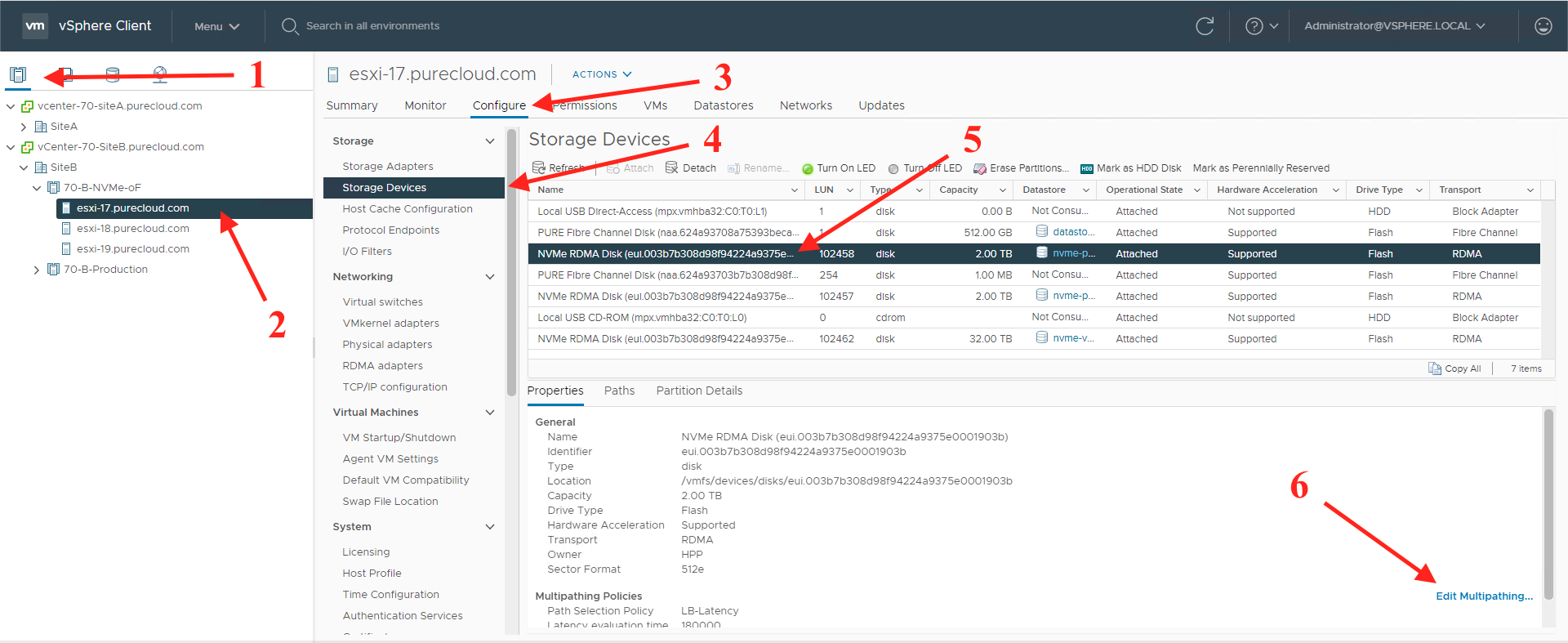
2. Select a host
3. Click on the Configure tab
4. Select Storage Devices
5. Select an NVMe device
6. Click “Edit Multipathing”
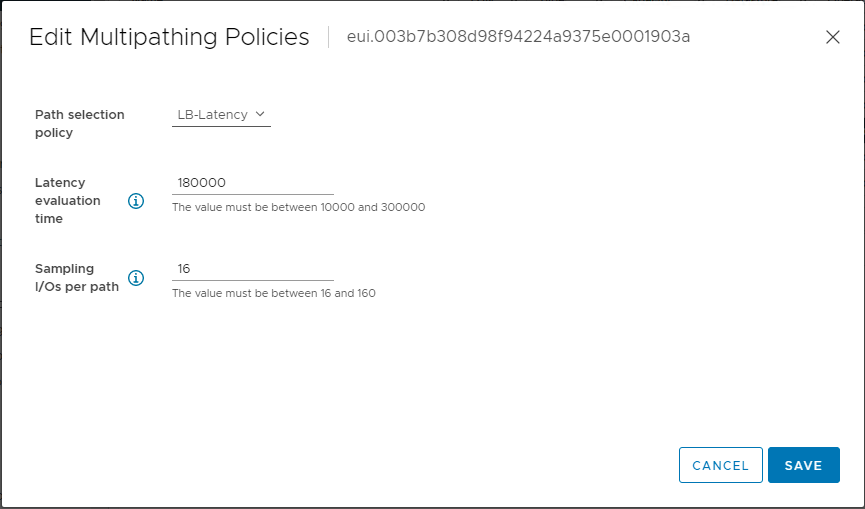
Once you are in the multipathing window, you have the option to change the path selection policy, the latency evaluation time and the sampling I/Os per path.
VMware has more detail on the options for esxcli storage core claimrule in this article.