
So in a blog series that I started a few weeks back (still working on finishing it), I wrote about managing snapshots and resignaturing of VMFS volumes. One of the posts was dedicated to why I would choose resignaturing over force mounting almost all of the time.
An obvious question after that post is, well when would I want to force mount? There is a situation where i think it is a decent option. A failover situation where the recovery site is the same site as the production site, in terms of compute/vCenter. The storage is what fails over to another array. This is a situation I see increasingly common as network pipes are getting bigger.
In this situation, you have hosts that have access to both the source and recovery array. In this case, the storage is configured with active/passive replication. So, let’s take the situation where the source storage array is gone. For whatever reason.
Your datastores will go APD and your VMs will stop responding. Messages like below will occur in the vmkernel log:
WARNING: ScsiDevice: 1700: Device :naa.624a937073e940225a2a52bb0001a2a2 has been removed or is permanently inaccessible. WARNING: HBX: 1728: 'FlashArrayVMFS02': HB at offset 3530752 - HB IO failed due to Permanent Device Loss (PDL)
The datastores will be shown to inaccessible in the GUI and the VMs will usually get a device loss error:
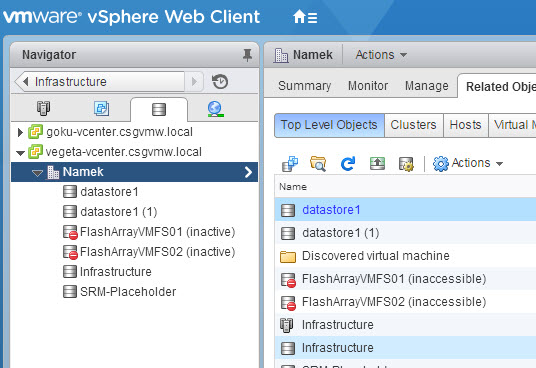
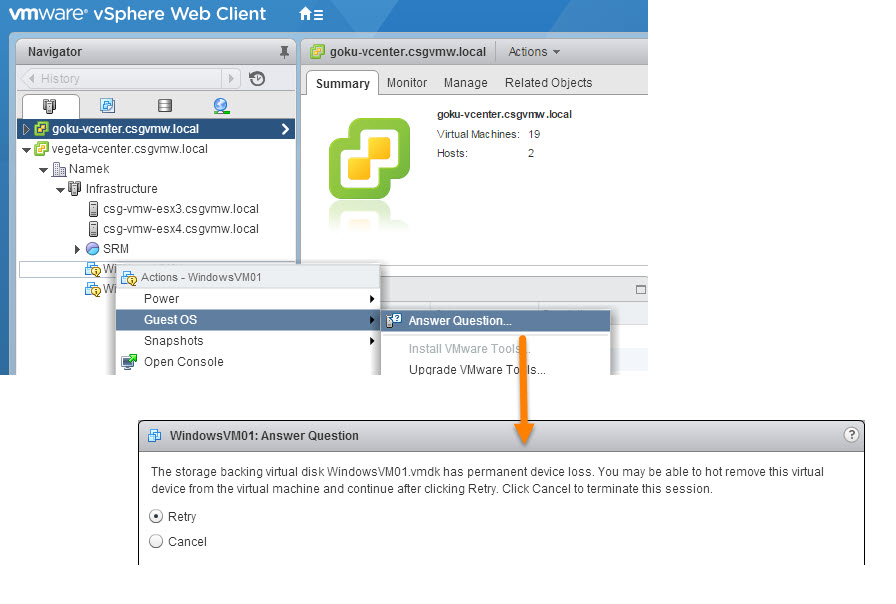
When the storage goes into PDL (Permanent Device Loss) the VMs will be marked with a question. It basically asks, hey the storage is gone, do you want this VM to keep trying to access it in hopes it comes back or should we just kill it? Hitting retry keeps it trying and cancel will power off the VM. The VM then is marked as inaccessible.
With the whole resignature process, in order to recover these VMs you would need to unregister them, mount the VMFS copy with the new signature then re-register them and power them on. If you do not reregister them the VMs will not see the recovered VMFS as the original volume. The VM sees it has a different signature and it thinks it is a new VMFS, even though the data is the same. See more information on signaturing here.
Resignaturing is required because a VMFS has been copied to a new volume with a different serial number. This is common in array-based replication, as a serial number is usually (though not always) tied to only being able to exist on one array.
That being said, you can “fool” ESXi into thinking that a VMFS is on the same volume as before, so the VMs will pick up where they left off with out unregistering/registering. This is force mounting. The function of force mounting is telling ESXi to ignore a signature mismatch and just mount the VMFS with a mismatched signature. This allows that VMFS to be presented on a different device than originally but with the same signature. Pre-existing references to that datastore will be restored!
There are a lot of problems that force mounting can introduce, and I linked to my previous post on that twice in this post already, so I won’t list them here. But let’s look at the two major benefits in this situation:
- Faster RTO. The removal of the need to unregister and re-register VMs greatly speeds up recover. The semi-long process of the resignature operation not having to happen also increases the speed.
- Historical information preservation. A problem with unregistering and re-registering VMs is that with many VMware and/or 3rd party management applications, when this happens the historical data for those VMs is trashed. Since the VM was unregistered, it is seen as no longer necessary. If the VM comes back after re-registration it is seen as a new VM. So the before and after data cannot be linked. In certain environments, this loss is a large problem.
This could be particularly of use in VDI environments where SRM involvement is messy, and where recovery vCenters may not exist and there a lot of VMs were registering/unregistering them all could mean a non-trivial extended RTO.
One could also argue, this simplifies recovery scripting, and it is partially true. But I think to really do this correctly you need a few extra steps that were not there before. You need to power down the VMs (if they were on during the failure), you need to still force mount the volumes etc. But really, more importantly, you do not want your VMs lingering on force mounted volumes for long, for reasons explained in that previous post. So I recommend provisioning new volumes and at some point shortly after the failover, Storage vMotion the VMs on the force-mounted volumes to the new properly signatured volumes.
The nice part of Storage vMotion on the FlashArray, is that it leverages VAAI XCOPY, and XCOPY on the FlashArray is just a metadata move, so moving the VMs is very fast operation and requires very little throughput/IOPS to do.
Then just delete the old force mounted volumes.
Another problem exists with vCenter, is that it only allows a VMFS to be force mounted on one ESXi host at a time, so this is not really reasonable for any shared storage environment as the VMs for a given datastore are likely to be spread across more than one host. So a solid possibility here is using an old (and hidden) advanced option.
WARNING: This option is hidden for a reason, VMware’s support with hidden options is not always there. So do NOT use this option without consulting with VMware support, especially in production environments.
In the ESX 3.x days (and earlier if I remember correctly), VMFS mounting/resignaturing, was not a volume by volume chore. It was done automatically when you rescanned the SCSI bus. Any unresolved volume would automatically be mounted (if possible) through either resignaturing or force mounting. And all of the volumes would be done in the same manner. So if you had five unresolved VMFS volumes presented, they would either all be resignatured, all be force-mounted or all be left alone.
This behavior was controlled by two advanced options:
- LVM.EnableResignature
- LVM.DisallowSnapshotLuns
Enable resignature (when enabled) would make all of your volumes resignatured, if DisallowSnapshotLuns was disabled (note the double negative there) any unresolved volume present would be force mounted. EnableResignature took precedence over DisallowSnapshotLun.
Good link about these options here:
http://www.yellow-bricks.com/2008/12/11/enableresignature-andor-disallowsnapshotlun/
The change in 4.x:
http://www.yellow-bricks.com/2011/04/07/per-volume-management-features-in-4-x/
These options were hidden in ESX(i) 4.0. Instead you could individually and selectively mount a volume with the mechanism of your choosing. These options have been hidden though, not removed. They still exist in ESXi 6.0 U1, though CLI usage of them will indicate they are deprecated and could be removed at any time. vCenter Site Recovery Manager still has the option of using the resignature option, so I am betting they will be here for some time yet, they have been deprecated for 6 years…
Anyways, disabling DisallowSnapshotLun, allows all of your VMFS volume copies to be force mounted during a rescan and the vCenter block against multiple host force mounting will be bypassed, because it happens at a much lower level. So if you present an unresolved VMFS to a cluster, a rescan of that cluster will force mount the volume on all of the hosts and all of your VMs on that datastore will return from being inaccessible! Easy as pie!
This can all be manually done, but I wrote a script to help you do the work. It does the following:
- Takes in a CSV file of source volume names and desired target volume names (They need to be different) and the cluster that pair should be recovered to
- Compares WWN values of the hosts in that cluster and figures out what FlashArray host objects relates to those hosts. It then figures out what host groups or hosts (or both/many) it needs to connect that volume to
- Identifies the latest remotely replicated snapshot for your given volume
- Creates new volume from that snapshot and a second volume of the same size
- Disabled DisallowSnapshotLuns on the ESXi hosts in the cluster for that given volume to allow force mounting
- Rescans and causes the datastores to be force mounted and VMs to become accessible again
- Powers on the VMs
- Creates a new VMFS on the respective datastores created earlier with the snapshot-based ones
- Storage vMotions the VMs from the force mounted VMFS to the properly mounted on. Does this for each datastore “pair”
- Unmounts, detaches, disconnects and destroys the VMFS/volume on the FlashArray
- Re-enables DisallowSnapshotLun
The CSV file looks like this:
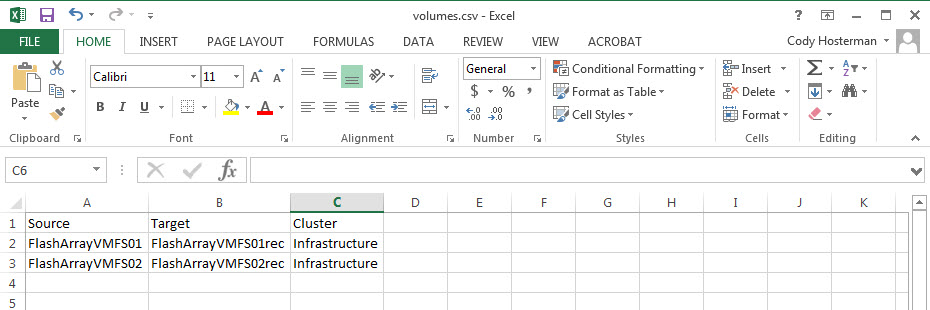
It needs three columns:
- Source FlashArray volume name
- Temporary volume name (this is the one created from the snapshot and force mounted)
- And the cluster to mount the volume to. If you don’t have clusters you will need to tweak the script a little.
Let’s look at a quick example. I have:
- I have a VM named “VM01”
- Running on a VMFS volume named “VMFS01”
- It is on a FlashArray named “FAsource” and the physical volume name is “VMFS01vol”
- It is replicating to a remote FlashArray named “FAtarget”
My CSV looks like so:

The volume “VMFS01volrecovery” does not exist right now.
The failure occurs and “VMFS01” goes away and my “VM01” is inaccessible. I start the script. It will:
- Shut down “VM01”
- Figure out the WWNs of cluster “Infrastructure” and relate it to host groups/hosts on the FlashArray “FAtarget”
- Find the latest snapshot on “FAtarget” of the volume “VMFS01vol” that was sent form the FlashArray “FAsource”
- DisallowSnapshotLuns is disabled on the target hosts.
- Creates a new volume on “FAtarget” with the name “VMFS01volrecovery” from that snapshot. This volume gets force mounted since it contains a copy of the original VMFS due to the snapshot
- Creates a volumes the same size of the “VMFS01volrecovery” volume with the name “VMFS01vol”. This volume gets mounted and formatted with a brand new VMFS since it is currently empty.
- The VMs get powered on the VMFS that is force mounted. That VMFS maintains the original name “VMFS01” but is on the FlashArray volume named “VMFS01volrecovery”
- The VMFS holding the VMs named “VMFS01” gets re-named to “VMFS01rec” after the VMs are powered on.
- The FlashArray volume named “VMFS01vol” gets formatted with VMFS and the VMFS name is “VMFS01” like the original name.
- The VMs are moved from “VMFS01rec” to “VMFS01”. They are moved off of the force mounted VMFS to the fresh one.
- When the VMs are all moved, the force mounted VMFS, now named “VMFS01rec” is unmounted and detached from the ESXi hosts. The underlying FlashArray volume called “VMFS01volrecovery” is deleted from the FlashArray.
- DisallowSnapshotLuns is re-enabled on the target hosts.
The script requires:
- PowerCLI 5.8+
- PowerShell 3+
- Pure Storage PowerShell SDK 1.0+
Get the script here:
https://github.com/codyhosterman/powercli/blob/master/disallowsnapshotlunfailover.ps1
See a video demo of the script below: