
This is a post that is somewhat a long time coming as I did the work for this jeez basically in August 2015, but never got around to actually writing a blog post. Shame on me. Anyways, here it is!
Let us start with the requirements:
- FlashArray 400 series or FlashArray//m
- Purity v4.1.1 (or higher)
- REST API: v1.4 (found in Purity v4.x and higher)
- Fibre Channel or iSCSI Protocol
- Commvault software version 10 service pack 12 or later with Commvault IntelliSnap software license
Some documentation links:
Pure Storage Community Commvault Page
FlashArray VMware & Commvault White Paper
The FlashArray VMware and Commvault WP goes over the detail on how the functionality works so I won’t go into tremendous detail here, but let’s highlight some important points.
Overview
First what does this integration do? Commvault’s IntelliSnap technology uses array-based snapshot functionality to create point-in-time copies of the data that needs to be backed up. This is generally aimed at short-term recovery/restore and not long-term retention (Commvault has other tech that focuses on the latter). Commvault coordinates with the end-application to create these snapshots, so the point-in-time snapshot is created in respect to the state of the application.
In the VMware IntelliSnap area, it is a similar level of coordination with VMware ESXi (a VM rather) as with an application like SQL or Oracle. This coordination is centered around of course some type of quiescing, with a VMware VM is uses the VMware snapshot feature with VMware tools to quiesce the virtual disk(s) prior to taking the FlashArray array-based snapshot. This VMware-snapshot behavior is optional, but is a default.
The restore model for IntelliSnap is pretty straight forward:
- Choose a ESXi host as the “proxy” host for restore operations
- Select virtual machines to protect with Commvault and the FlashArray
- Whether you are restoring a file in the guest, a virtual disk or an entire virtual machine, the FlashArray snapshot is mounted to the host and then Commvault does what it needs to do.
The recovered file, VMDK or VM can either replace the existing one or be mounted/recovered elsewhere for test/purposes or for some type of manual recovery or settings comparison.
The recovery process from a FlashArray perspective is as follows:
- Identify a snapshot to recover from–this is simply a time range you choose (or just the latest snapshot). If you choose a time range, Commvault will identify the latest FlashArray snapshot in that time range and use that one.
- A new volume will then be automatically created by Commvault using our REST API that has the same geometry (size) as the original volume that is reflected by the point-in-time of the snapshot.
- The meta data is then copied to the new volume therefore assigning that volume the proper data
- The volume is then connected to the proper host object on the FlashArray as indicated in your recovery/proxy ESXi host in Commvault. That host has to be zoned and created on the FlashArray first (a one-time operation).
- The host is rescanned and then the volume is resignatured and ready to use
Registering a FlashArray is a pretty simple process in Commvault–give the FQDN or Virtual IP of the FlashArray(s) and credentials. See the white paper for details on that.
Advanced Configuration
As far as advanced configuration there isn’t much to consider. The following is the “Snap configuration” screen to see for Pure Storage in Commvault:
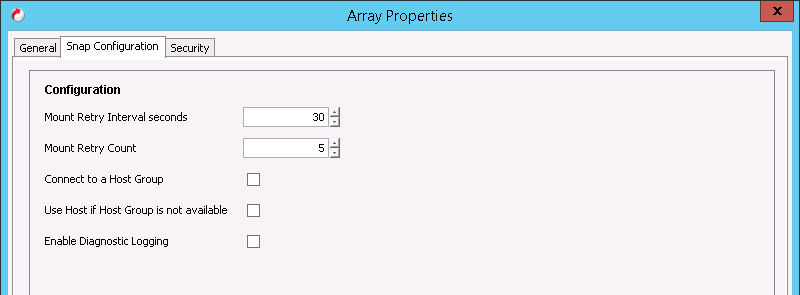
In a VMware environment there should be very little reason to change either of the numbers (mount retries). If mount is failing with the default settings, I would recommend opening a support case with Commvault first–something is probably screwy. Diagnostic Logging is pretty self-explanatory, the settings that might spark questions are the ones related to host groups.
Before I continue, ALL of these settings are available when registering an array with Commvault. That being said, ALL of these settings can be overridden at a much more specific level (single operation or function). I highly recommend only changing them for discrete operations, not for the entire array. Otherwise every operation will use non-default settings unless specifically overridden. Furthermore, I generally recommend never changing these defaults unless you have a good reason.
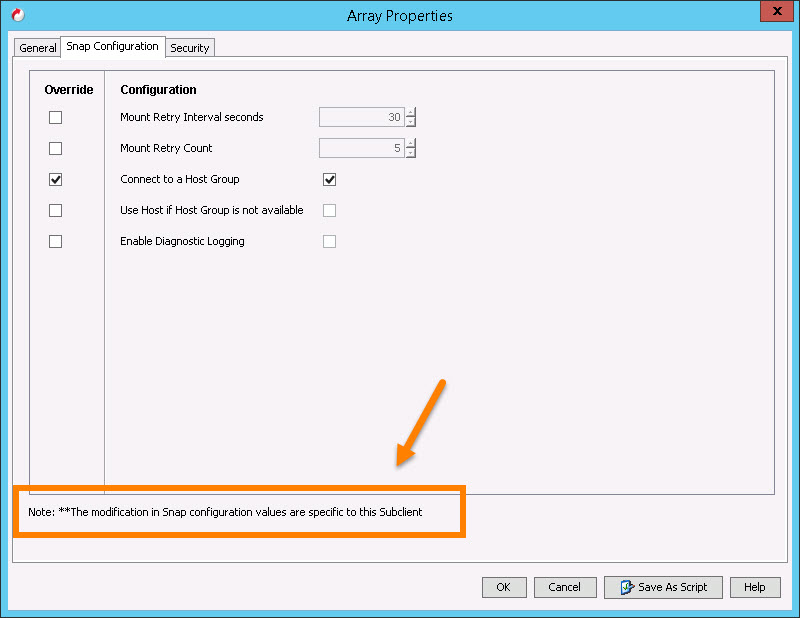
This begs the question, why not connect to a host group instead of a host? The more, the merrier, right?
Well first let’s review what a host group is. A host group is a collection of host objects on a FlashArray that you can provision to atomically. In other words, you add a volume to a host group all of its hosts will get that volume. A host is a collection of WWNs or IQNs which can all be provisioned to directly. The host group is a handy provisioning object for provisioning to VMware clusters for instance.
So if you add a volume to a host group, all of the hosts get it. Sweet–standard stuff. The point of contention here, is that we recommend mounting Commvault IntelliSnap recovery VMFS volumes only to one host. Why? Well Commvault asks you to select one ESXi host as the recovery host–not a cluster. So, it will only rescan that host, and when it removes that volume it will only unmount the VMFS and run a detach operation on that volume.
The recovery volume is usually not meant for long term storage–it is usually meant to be used for a short term recovery operation; present a copy of an existing VMFS, extract some data from it, and then get rid of it.
If a volume is presented to a host group a rescan of the other ESXi hosts will cause all of those other hosts to see it and mount it. When it is removed, it will only be gracefully removed from the target proxy ESXi hosts, the other ones it will be ripped out from under them. This can lead to issues in VMware environments (this best practice for device removal still exists for a reason). A lot of these device loss issues have been resolved or ameliorated in recent ESXi releases, but the chance for problems can still exist. Therefore connecting to a host group in this situation is not recommended. If you choose this option, after the unmount operation you will see errors like this on all of your other hosts in the cluster/host group:
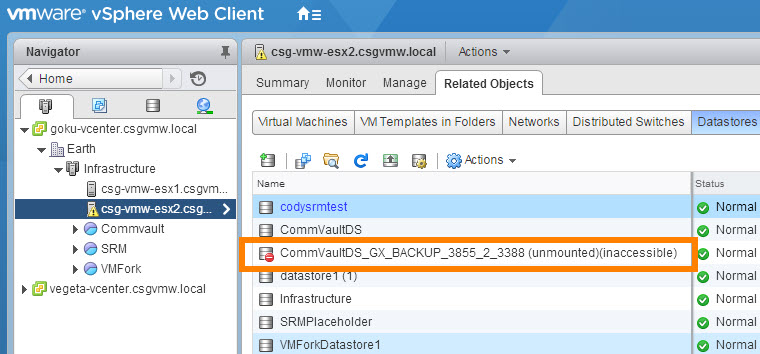
It can usually be cleared up with a rescan, but it is best practice to try to avoid this situation. So long story short, keep the defaults.
Snap Naming Conventions
When a snapshot is created (either a one-off operation or a schedule) the snapshot will look like below:
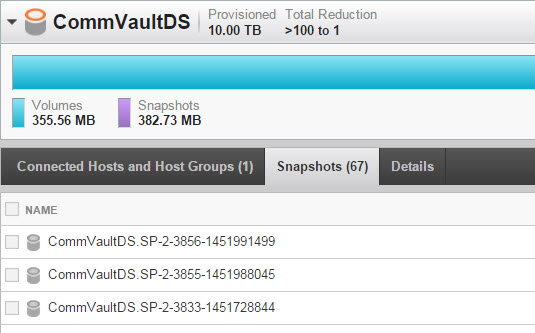
The name consists of:
- Primary Name of the Volume
- CommCell ID # (SP-x)
- Job ID (xxxx)
- Epoch Time (xxxxxxxxxx)
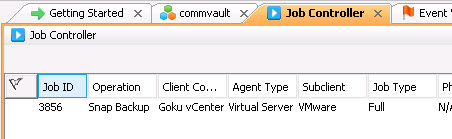
The job ID can be found in the variety of places–the top one in the above image (3856) was an one-off snapshot/backup operation:
Commvault will automatically create recovery volumes during every recovery operation–like mentioned earlier–they are meant to be temporary. So the volume and VMFS names are meant to be descriptive, while not necessarily friendly to your memory.
The VMFS and volume name for recovered volumes is a bit different. A volume name looks like so:
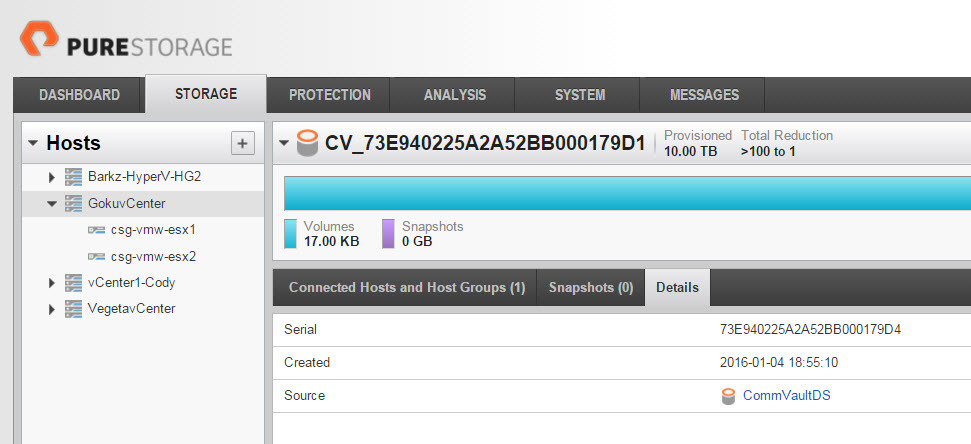
The name for this one is CV_73E940225A2A52BB000179D1, not exactly what I would name my child, but works for a temporary volume name. CV stands for Commvault (that I am guessing, but I feel confident in that) and the rest of the name is a bunch of letters and numbers. You might recognize the number though and you would be right–it is not randomly assigned by Commvault. Instead it is a FlashArray object serial number. Note though, that it is not the serial number of the volume itself, but instead the serial number of the snapshot it came from. Snapshot volumes numbers are not in the GUI, but only in the CLI or REST API. From the CLI, you can see it is from this snapshot:

The VMFS does not use the same naming convention. When it is resignatured, ESXi just takes the original name plus a snap-XXXXXXX suffix. Commvault changes this to be like so:
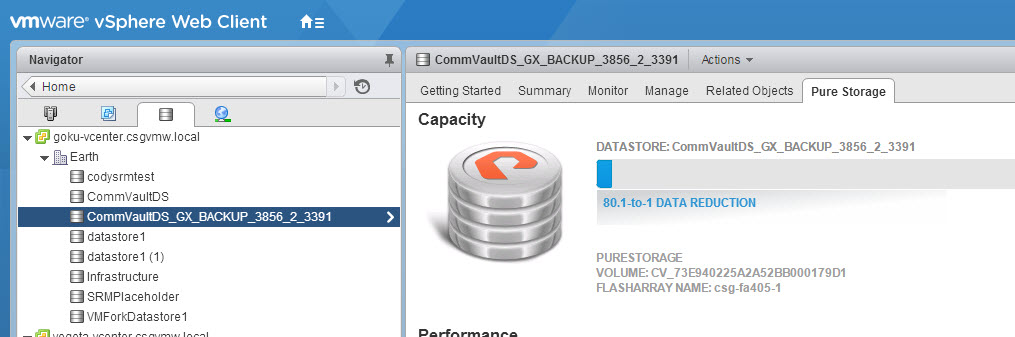
CommVaultDS_GX_BACKUP_3856_2_3391
The original datastore name is the prefix (CommVaultDS), then _GX_BACKUP_ is added followed by the backup job ID then the Commcell ID and then the archive file ID for that backup.
Authentication
Last topic I want to cover quickly is authentication. The standard process for authentication for our REST API is a token exchange:
- Send your user name and password
- Receive your API token
- Send the API token back
- Creates a session between the host and FlashArray
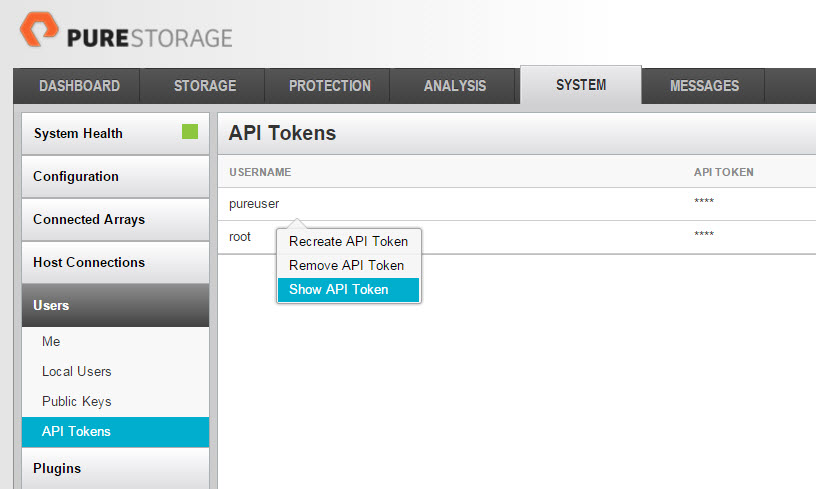
The Commvault IntelliSnap technology skips steps 1 and 2. Instead when registering your FlashArray just supply it with your username and your API token which can be retrieved from the FlashArray GUI or CLI (or REST if you so choose).
So that’s the general stuff to know about Commvault IntelliSnap and the FlashArray. Read the white paper for more details on the exact workflows. Refer to the following narrated videos for examples of the different recovery process as well.
The videos respectively are:
- FlashArray configuration and authentication with Commvault IntelliSnap
- Creating a IntelliSnap technology snapshot on the FlashArray
- Mounting a FlashArray snapshot with IntelliSnap
- Recovering a virtual machine from a FlashArray snapshot with IntelliSnap
- Recovering a file inside a virtual machine from a FlashArray snapshot with IntelliSnap
How does the array ‘copy’ the snap to the CV media server? When specifying the Pure array, we are only providing the management address, nothing on the iSCSI network.
Does the snap only go over the management connection?
Last I looked at this (admittedly it has been years) they dont store any real data on their media server when intellisnap is enabled. They store metadata/catalog of our snapshots so they know what is on there as they coordinate the snapshots, but the data is preserved on the FA. Though I know they have done more work on this since I was directly involved. We do have SnapDiff in our REST API, so snapshots can actually be differenced in the API–I know some backup integrations (e.g. Cohesity) leverage this feature.
All you’re giving CV is connection info to be able to talk to the array. It will dynamically figure out all the relationships it needs for whatever task it’s doing. Cody’s right that for the snap itself CV is only storing index information about the snap contents (plus metadata about the snap itself that goes in the main DB), that doesn’t cover access for reading or moving data–backup, restore, live recovery, etc.–and I think that’s what you’re asking for.
For snap access, CV will look at the mount host and get the iSCSI iQN and/or FC WWNs. It uses those to figure out the host you defined on the array, and from there the host group, if you pick that option. It then maps the temp volume it created from the snap to that host or host group. When the task is finished it unmaps and destroys the temp volume. This is the same for any task that needs to access the snap, on any platform or protocol.
Thanks Roy!!!
Can you please help me with the below query.
How does intellisnap incremental and full backup work?
It is mentioned that intellisnap informs storage array to take snapshot. How does array know whether it is incremental or full backup?