
Storage capacity reporting seems like a pretty straight forward topic. How much storage am I using? But when you introduce the concept of multiple levels of thin provisioning AND data reduction into it, all usage is not equal (does it compress well? does it dedupe well? is it zeroes?).
This multi-part series will break it down in the following sections:
- VMFS and thin virtual disks
- VMFS and thick virtual disks
- Thoughts on VMFS Capacity Reporting
- VVols and capacity reporting
- VVols and UNMAP
Let’s talk about the ins and outs of these in detail, then of course finish it up with why VVols makes this so much better.
NOTE: Examples in this are given from a FlashArray perspective. So mileage may vary depending on the type of array you have. The VMFS and above layer though are the same for all. This is the benefit of VMFS–it abstracts the physical layer. This is also the downside, as I will describe in these posts.
Thin Virtual Disks and VMFS
I will start with thin virtual disks. There are quite a few benefits with thin virtual disks–and it is mostly centered around their flexibility. In my opinion one of the major benefits is in-guest UNMAP, which I have blogged about extensively:
High level, what is a thin virtual disk? It is a disk that is assigned a logical size and presented to a virtual machine. So if you create a 50 GB thin virtual disk, the virtual machine sees a 50 DB “disk” usable for whatever file system it wants to put on it. On the VMFS, a VMDK file is created, which is where the data gets written to. The fundamental characteristic of a thin virtual disk is that the file that “is” the virtual disk does not take up 50 GB on the VMFS. It takes up space only as the VM writes to it. So if the VM writes 5 GB of data, that virtual disk takes up 5 GB of data on the VMFS.
There are some performance questions around thin of course too. See more information around that here:
Pure Storage FlashArray and Re-Examining VMware Virtual Disk Types
Let’s walk through this.
Creating a thin virtual disk
Here is a VMFS with nothing on it:
![]()
Well empty besides the VMFS metadata, which VMFS reports as 1.47 GB. Let’s look at the array itself.
![]()
2 MB. Is it reducing 1.47 GB down to 2 MB? No of course not, the array is reporting a data reduction ratio of 21:1. So it really only sees ~40 MB written. I have many VMFS datastores on this array, so the vast majority of this VMFS metadata is deduped away.
The point is that there are three things at play that cause this discrepancy:
- Allocated vs written. ESXi allocates space on the file system for many reasons, virtual disks being the primary one, but quite often does not actually subsequently write anything immediately. So the array is unaware of this allocation. A virtual disk allocation is a METADATA change on VMFS. Not a data write down to the array. Hence mismatch.
- Data reduction. What is actually written by ESXi (or its VMs) gets reduced at least somewhat by the array. So the array footprint is smaller. Hence mismatch.
- Zero Removal. We (Pure) do not include things like zero removal in our data reduction ratio. So if the data that is written is actually a bunch of zeroes, it won’t really be reflected on the FlashArray. A lot of the VMFS metadata space is zeroed upon creation. Hence mismatch.
So let’s put a thin virtual disk on the VMFS. 40 GB in size.
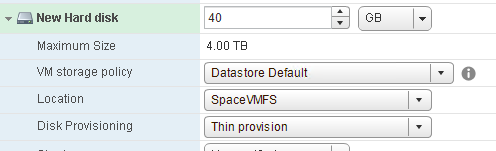
How does a thin virtual disk work? Well it only allocates as needed. As data is written to it eventually by the guest, it extends itself one block at a time, then zeroes those blocks out, then commits the data. So here is the VMFS after I added a thin virtual disk:
![]()
Still just 1.47 GB on the VMFS, so: no change.
![]()
Still around 2 MB on the FlasArray.
If we look at the VMDK file, we see it is indeed 0 KB in size:
![]()
Zeroing a thin virtual disk
To elucidate the zeroing behavior, let’s write zeroes first. This is a Windows machine, so I will use sDelete to write zeroes. Simplest option.
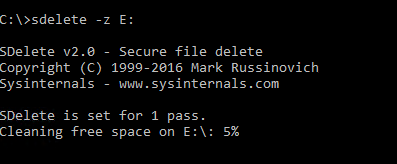
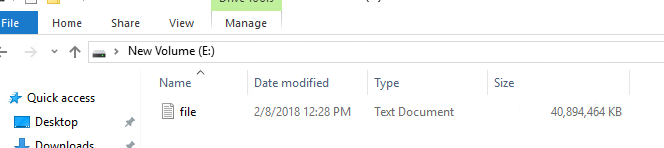
This will write zeroes to the entirety of my E: drive–all 40 GB. So let’s take a look at it. After the process completes, Windows is still reporting the NTFS on my thin virtual disk as empty:
![]()
But what about the VMDK itself?
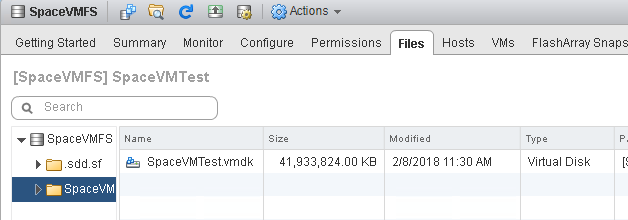
All the way up to 40 GB! VMware doesn’t know what was written–it does not know that it was all useless zeroes. ESXi of course saw writes to blocks, so it allocated those blocks-therefore growing the thin virtual disk (the VMDK file). The data was then sent to the array. How does that look?
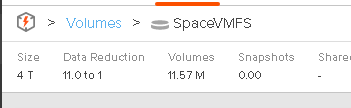
11 MB. So nothing. This is because the FlashArray discards all of those zeroes. Since we don’t include zeroes in our data reduction ratio, it doesn’t change either.
So before we move on, let’s recap. Windows sees zero GB. VMFS sees 40 GB. The FlashArray sees essentially zero GB. So if we have three people (Windows admin, VMware admin and Storage admin), two are happy (Windows/Storage) and one is not (VMware).
Is it possible to shrink the virtual disk? Yes. VMware does have a feature in vmkfstools called “punchzero” that can be used to read through a virtual disk and remove blocks that are all zero and deallocate them on VMFS–effectively shrinking the virtual disk. Note though, that this is an offline procedure. The virtual disk must either be removed from the VM, or the VM must be shutdown. This KB describes this process:
https://kb.vmware.com/s/article/2004155
Writing to a thin virtual disk
Moving on. Let’s now restart, delete and re-create the virtual disk. So all three report the same thing. So back to zero/zero/zero.
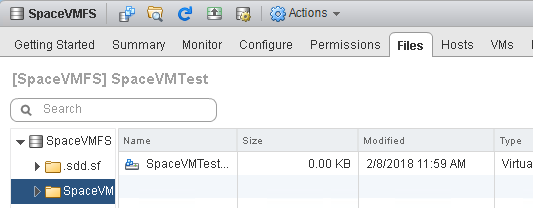
I now use vdbench to create a non-zero file and fill up my E: drive (which sits on my thin virtual disk).
If we look at the VMFS, we see the VMDK has gone back up to 40 GB:
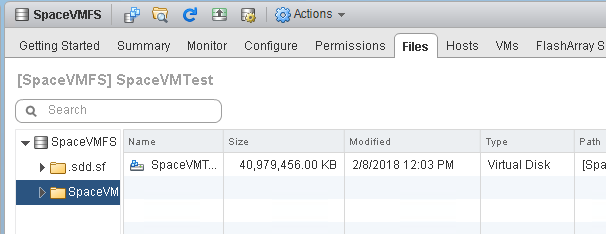
If we look at the FlashArray:
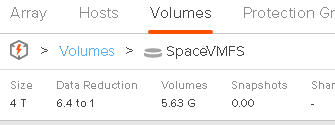
It is reporting 5.6 GB. So the FlashArray data reduction has reduced the 40 GB of data written by the VM (vdbench) down to 5.6 GB physically.
So Windows is reporting 40 GB used, VMFS is reporting 40 GB as used and the FlashArray is reporting 5.6 GB. In this case, the disrepancy is due to FlashArray data reduction.
Deleting data in a thin virtual disk
What happens if we delete this file created by VDBench from the NTFS on my thin virtual disk?
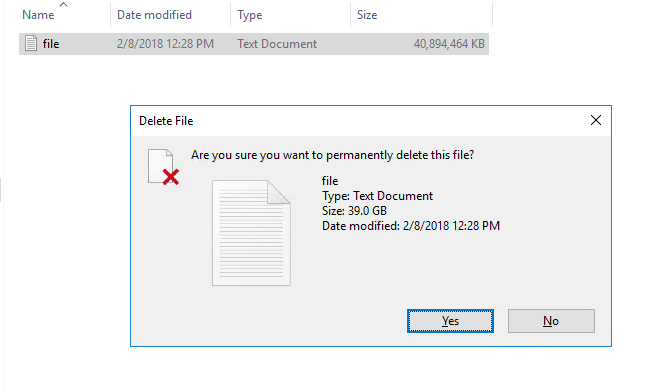
Well now NTFS on the VMDK is empty:
![]()
But the VMFS still reports the VMDK file as 40 GB:
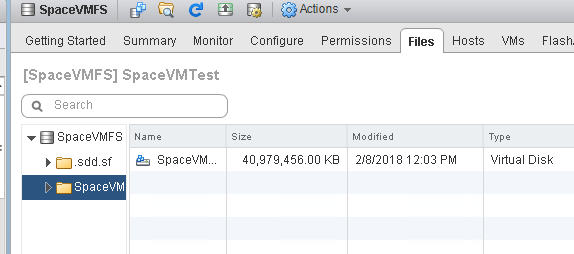
And the FlashArray does not change its reporting either:
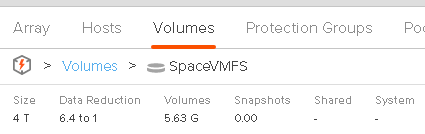
So now Windows is reporting 0 GB. VMFS reports 40 GB. The FlashArray reports 5.6 GB.
Let’s think about this for a second:
- The guest OS (in this case Windows) reports how much it currently has written. This case, it is now zero. The file has been deleted.
- VMFS reports how much has been allocated. If the written goes down, the allocated does not. They are different things. VMFS does not know that the file has been deleted in the VM, so the allocated size of the virtual disk stays at 40 GB.
- The array reports the physical footprint of what was last written in total. It stays that way until it is overwritten. If something is simply deleted, and there is no overwrite, so the array is unaware. Exactly the size of the footprint is dictated by how/if the array uses data reduction.
These are all different metrics and therefore mean different things.
So how do we get VMware and the array to reflect what is actually in-use by the guest? Well there are a variety of methods, but it usually boils down to two options:
- Writing zeroes
- In-guest UNMAP
Writing zeros is supported with all versions of ESXi in all configurations, so let’s look at that first.
Reclaiming space by zeroing a thin virtual disk
If you use sDelete, in the case of Windows, (or dd from /dev/zero for Linux) you can zero out the free space in the file system. Most arrays these days have the ability to automatically remove zeroes (like the FlashArray) or have a zero space reclamation procedure you can run after the fact.
So if I run sDelete, the VMDK size doesn’t change. Still 40 GB.
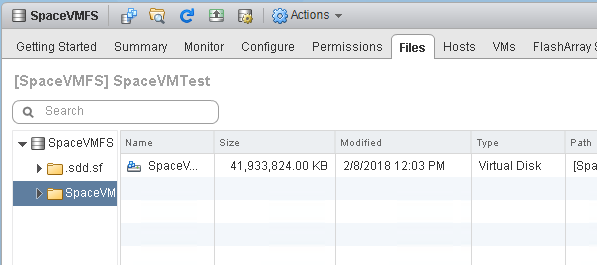
This is because ESXi just sees writes. The allocation of the VMDK is already full, so no changes are needed.
The FlashArray though does respond.
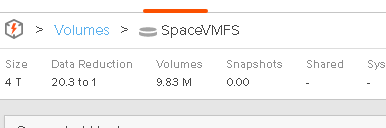
The FlashArray sees the new data being written, so it discards the previous data. Since the new data is all zeroes it discards these writes too.
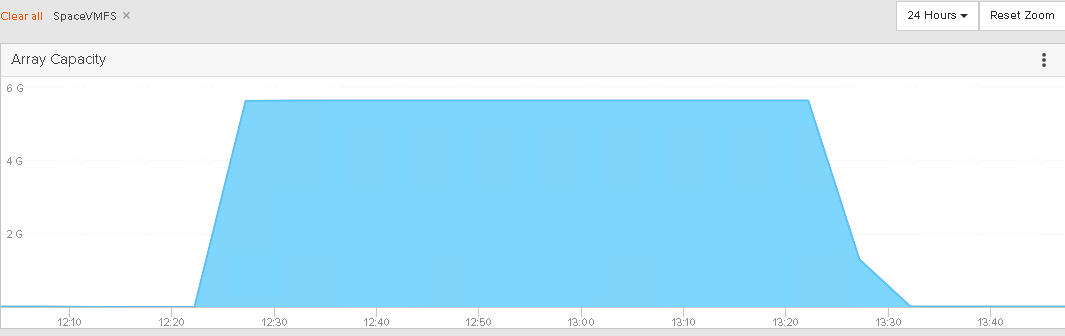
The virtual disk though is still reporting 40 GB. This is because no one has told VMFS that the data is not needed. How does it know that the zeroes aren’t needed? It doesn’t.
So to shrink the VMDK, you need to tell VMware to reclaim the zeroes. This can be done by removing the VMDK from the VM (or shutting the VM down and running vmkfstools punchzero:

Of course the downside of this is that it is offline.
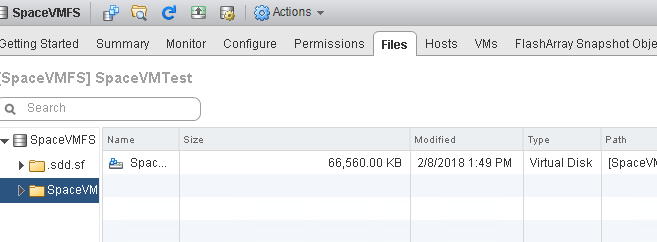
When the punch zero is done, the VMDK is down in size. From 40 GB to about 70 MB.
The other option is UNMAP. This is a much cleaner option and is online. But it does have restrictions.
Reclaiming space with UNMAP in a thin virtual disk
In-guest UNMAP allows the guest OS to issue UNMAP SCSI commands to the file system on a VMDK to blocks that are not in use, this in turn is intercepted by ESXi. ESXi then shrinks the virtual disk, deallocating the VMDK where the UNMAP operations were sent. Then, depending on the configuration, ESXi will issue UNMAP to the underlying volume on the array. The array receives UNMAP and simply removes the written allocations it has for those blocks. In effect, achieving all of the zeroing steps, in one, built-in, online procedure.
For how to do this, refer to the following blog posts:
The following restrictions apply:
- Virtual disk must be thin
- For Windows to work, it must be at least ESXi 6.0
- For Linux to work, it must be ESXi 6.5
- If Change Block Tracking is enabled on that VM, the ESXi version must be 6.5+
- If the VMDK has a VMware snapshot, it will not work
- With VMFS-5, for the UNMAP to be sent to the array, the ESXi option EnableBlockDelete must be enabled
- For VMFS-6, for the UNMAP to be sent to the array, automatic reclamation must be enabled.
For example, I have a thin virtual disk with NTFS on it, and I wrote 40 GB of data:
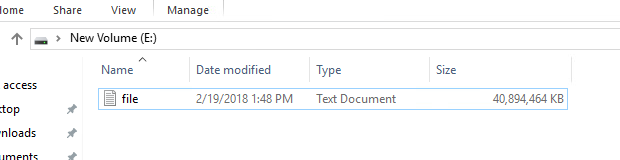
Which translates to my VMFS showing the VMDK file as being 40 GB:
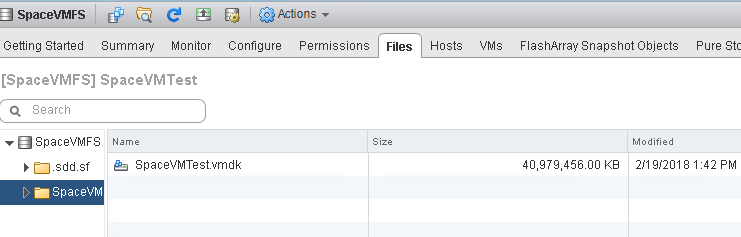
And finally around 5.6 GB on my FlashArray (due to data reduction):
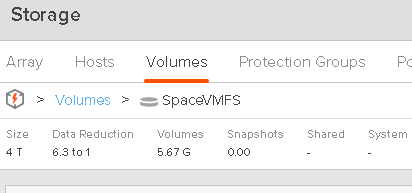
So now I delete the file. Instead of the zeroing option, I can go the UNMAP route, since I have the pre-requisites filled out.
Windows can do it automatically (which is enabled by default, or it can do it manually via the Disk Optimizer tool (or optimize-drive from PowerShell).
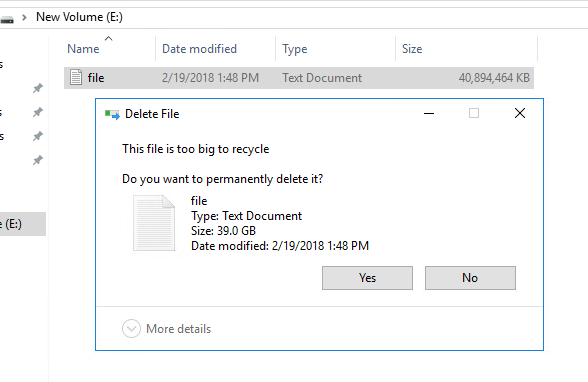
Windows will issue UNMAP (make sure DisableDeleteNotify in Windows is set to 0, it should be–this is default). UNMAP will be sent to the VMDK and ESXi will shrink the VMDK down by the amount of blocks that were reclaimed in the VM. So my VMDK is back down to about 80 MB–from 40 GB.
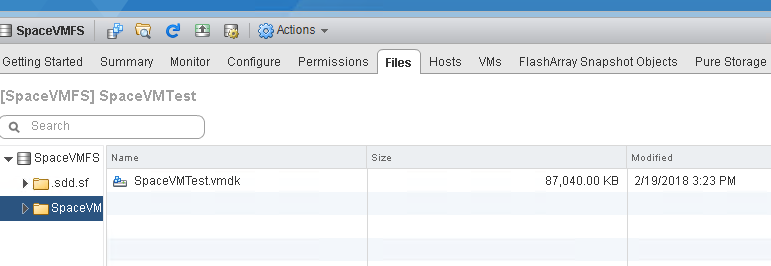
If we look at my FlashArray the space is reclaimed as well.
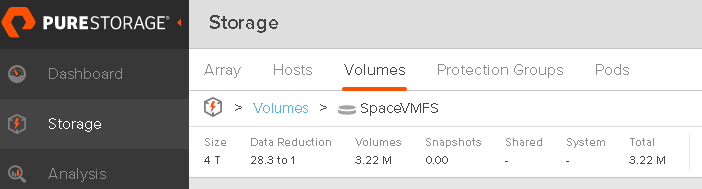
And over time:
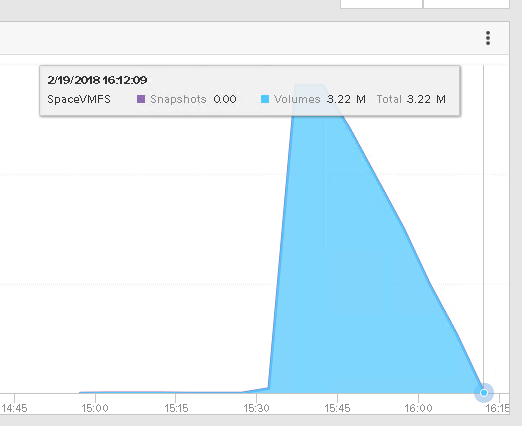
So UNMAP in the guest is really what makes the application and VMware layer accurately reflect one another. This is enabled by of course the use of thin virtual disks.
Deleting a thin virtual disk
The last thing is, what happens when we delete the virtual disk? Well it is certainly removed from the VM and the VMFS. But how does the array know? Well it doesn’t by default. The deletion of a VMDK is very similar to a deletion of a file in your VM–the layer below doesn’t know about it.
I filled my VMDK back up:
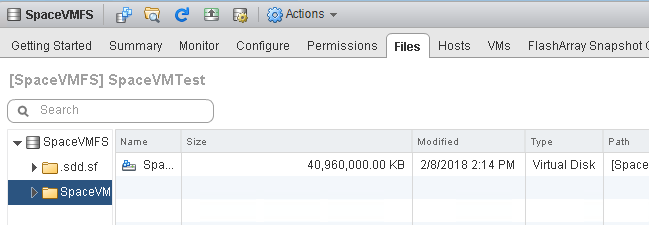
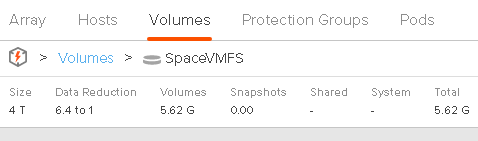
Then deleted it:

Making the VMFS back to 1.47 GB again:
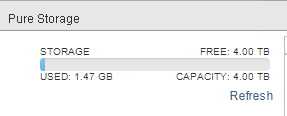
But my array volume is still reporting the space:
How do I reclaim this? Well this is called VMFS UNMAP. When a file is deleted from VMFS, UNMAP needs to be issued to the array to tell it that the space is freed up.
- In VMFS-5 this is manual, using the esxcli storage vmfs UNMAP command as seen in this post VMware Dead Space Reclamation (UNMAP) and Pure Storage
- In VMFS-6 it is automatic, as seen in this post: What’s new in ESXi 6.5 Storage Part I: UNMAP
Once run (whether VMFS-6 did it automatically, or you ran it for VMFS-5 via a script or something) the space on the array is reclaimed.
Part I Conclusion
In the end, coordination between the different layers is tough. Though the flexibility of thin disks make it a bit easier.
There are two directions of communication in the storage stack. From the bottom up and from the top down of course.
The process starts with the array saying how much capacity a volume can offer. ESXi than takes that number and creates a file system that describes it. The VMware user than takes some amount of that and presents it up to the VM as a volume. This is a virtual disk. The VM OS then puts a file system on that to represent and track that space for applications. That is really the only communication from bottom up. The rest goes top down. There is no mechanism for the array, to say “hey, no–you have written this much”. Because in the end, the top level is the true arbiter of that.
Most of the communication goes top down. A VM OS writes data. This makes a change to the metadata of the file system and then commits some data. That data is then written to the virtual disk. This, in a thin world, tells the VMDK to grow. It is allowed to grow until its written size is equal to its created size. This written size is reflected in VMFS as the allocated size of the disk.
This data is then written to the storage and the storage reduces (or expands it) as needed. If you don’t have data reduction it might actually take up MORE space, because of RAID overhead etc.
Thin provisioning is a concept that allows the underlying layer to still only reflect what has been written–it reflects this by allocating a block. VMDK file size. Storage array written usage. Etc. But once it has been written it stays that way. So even if the written changes, the allocation persists.
To fix this discrepancy, UNMAP is used. UNMAP tells the layer below, “yeah I know I wrote to that once, but I don’t need it any more”. This translates from the guest to the VMDK in the form of the VMDK shrinking. This translates from VMFS to the array as the physical blocks being deallocated and freed up.
In other words, UNMAP tells the layer below that something has changed and data is no longer needed. This is needed in the guest, and in ESXi. UNMAP execution makes the virtual disk size align with the VM OS file system. And then storage volume align with what VMFS sees as used.
So understanding how your array reports data is important. The VMFS layer and the VM layer is consistent. Arrays work differently.
This is a major reason why VMFS can’t report on data reduction–too much variation and no mechanism to override.
Next post let’s look at eagerzeroedthick virtual disks. Coming soon.
Do you have any good techniques for determining VMs that are wasting space on the Pure?
It is tricky frankly–especially if you are not using thin virtual disks. RVtools can be a nice quick way to see differences https://www.robware.net/rvtools/.
Thin is easiest–if the used space in the guest is less than the size of the VMDK, then you have dead space.
Thick is tougher. Though not impossible. If you have a method for reading out the “used” space in a guest and then adding that metric to all of the used space results for all of the VMs on a datastore and then comparing it to the thin provisioning metric on the FlashArray (described here https://www.codyhosterman.com/2017/01/detecting-what-flasharray-vmfs-volumes-have-dead-space/) you can identify how much VM dead space you have on that datastore. Finding out which VM though is a bit of a guessing game with thick though because the VMDK is always reported as full. I can dig a bit more into this though.
This all is SO MUCH better with VVols…