
Yes. Any questions?
Ahem, I suppose I will prove it out. The real answer is, well maybe. Depends on the array.
So debates have raged on for quite some time around performance of virtual disk types and while the difference has diminished drastically over the years, eagerzeroedthick has always out-performed thin. And therefore many users opted to not use thin virtual disks because of it.
So first off, why the difference?
Well I won’t spend a lot of time going into the difference between eagerzeroedthick and thin. But at a high level the difference is two things.
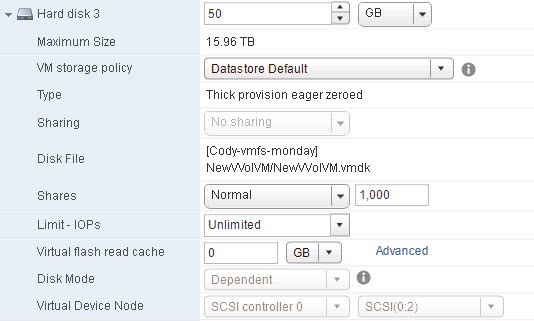
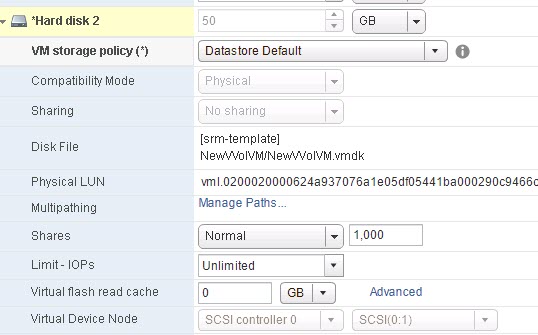
Eagerzeroedthick: When a EZT virtual disk is created, ESXi first allocates the entire virtual disk on the VMFS prior to it being used. Therefore if the virtual disk was created to be 50 GB, it consumes 50 GB of space on the VMFS. Furthermore, prior to being able to be used, a EZT virtual disk is fully zeroed out. ESXi will either use WRITE SAME to issue pattern zero write requests to the entire virtual disk (if the storage supports WRITE SAME) or it will literally write zeroes to the entire disk. WRITE SAME is far more efficient and much faster in general. Either way, the virtual disk cannot be used until that process is done.
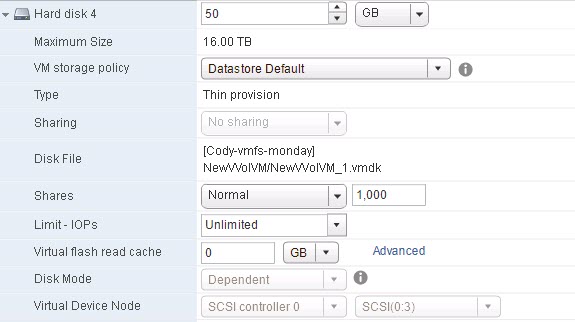
Thin: thin virtual disks are neither pre-allocated or pre-zeroed. Instead, when created, the virtual disk only consumes one block on the VMFS. When the guest writes to it, the blocks are then allocated as needed. This is why thin virtual disks “grow” over time on the VMFS. Furthermore, before a newly allocated block can be written to, it must be zeroed (once again using WRITE SAME or traditional zeroing). So when a write is issued by a guest to a thin virtual disk to a previously unallocated segment, it must wait for first the thin disk to be grown then for it to be zeroed. Therefore these new writes have a latency penalty. Of course once it has been written to, the impact is gone.
So it is fairly understandable why one might choose EZT over thin. But what about VVols?
VVols do have the concept of thin and thick. But what that means is really entirely up to the storage vendor. For an array like the Pure Storage FlashArray, thick provisioning does not make much sense because it dedupes and removes zeroes. So even pre-zeroing is generally useless because the array just removes the zeroes once they are written.
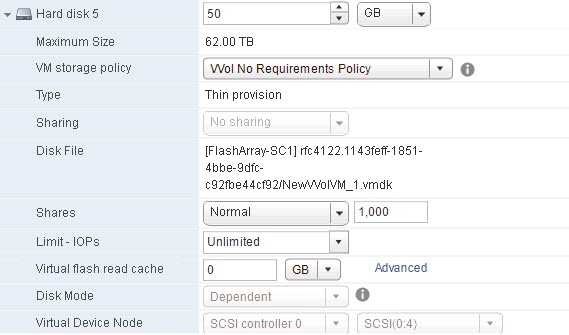
So on the FlashArray, there is no zeroing of VVols. Thin VVols are no exception. Thin VVols are thin only in the sense that they don’t reserve any data on the array until the guest OS writes to it. It differs from thin VMDKs in this way when ESXi requires it to be zeroed out.
So with thin VVols you get all of the benefits of thin (online resize, in-guest UNMAP, no wasted allocation) but not the downside: performance penalties.
So let’s prove this out.
I will run four tests:
- Physical RDM (drive E:)
- EZT VMDK (drive F:)
- Thin VMDK (drive G:)
- Thin VVol (drive H:)
All disks are presented without a filesystem so to avoid any “warming up” that perf generators do when performance testing file systems. The warm can mask the difference between thin and thick due to the warm up causing the zero allocations prior to the actual test.
I will be using VDBench with a simple 100% write workload with 32 KB I/Os set to do 2,000 IOPS. So the variable here will be latency.
Performance Testing
So let’s first create a baseline. Using a physical mode RDM–this is running without any kind of virtualization in the middle of the data path.
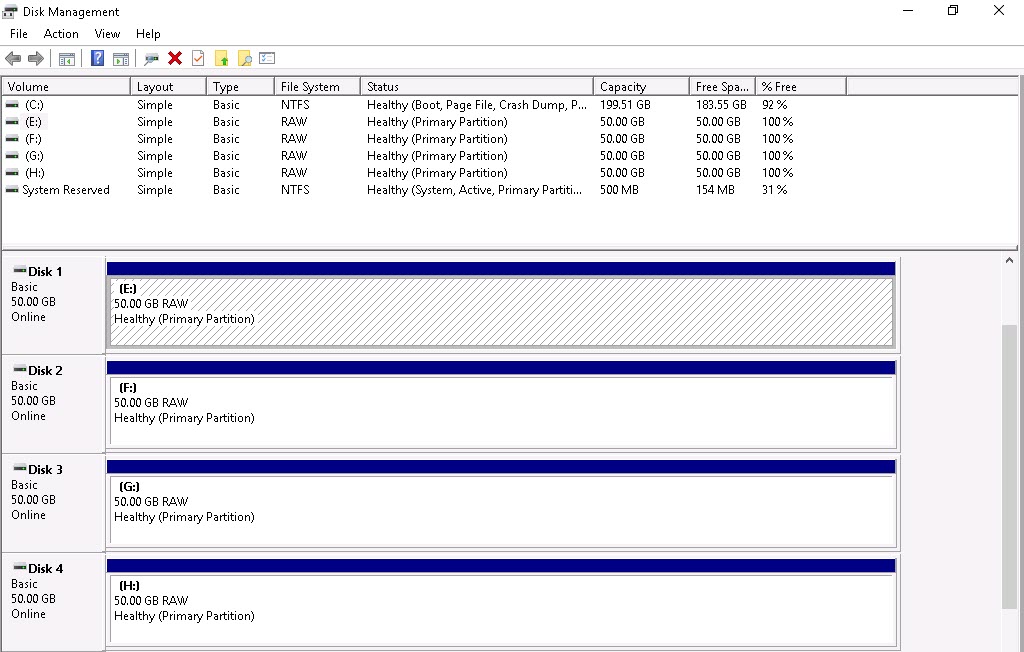
Here is the perfmon report from my VDbench workload for the RDM:
The report shows the latency in milliseconds of the workload. As you can see it is nicely and consistently .5 ms.
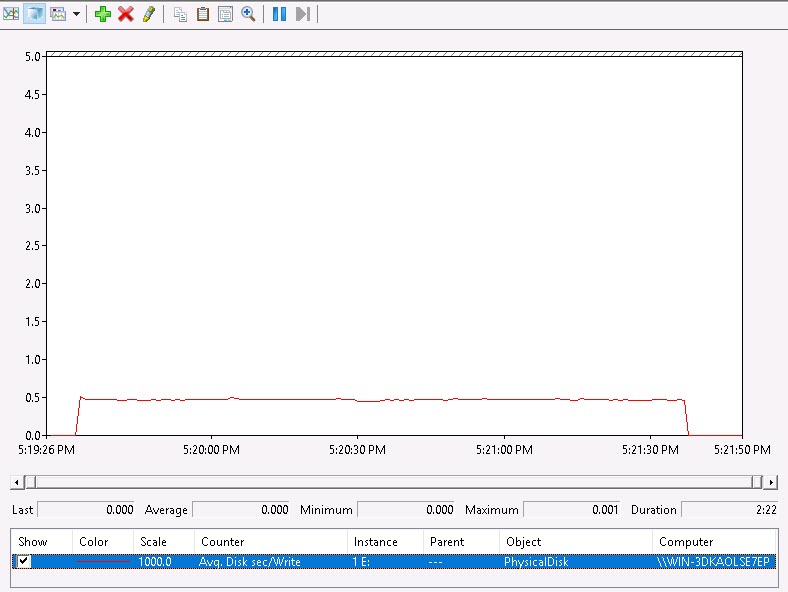
Now for eagerzeroedthick:
Same thing. Consistent performance, .5 ms latency throughout.
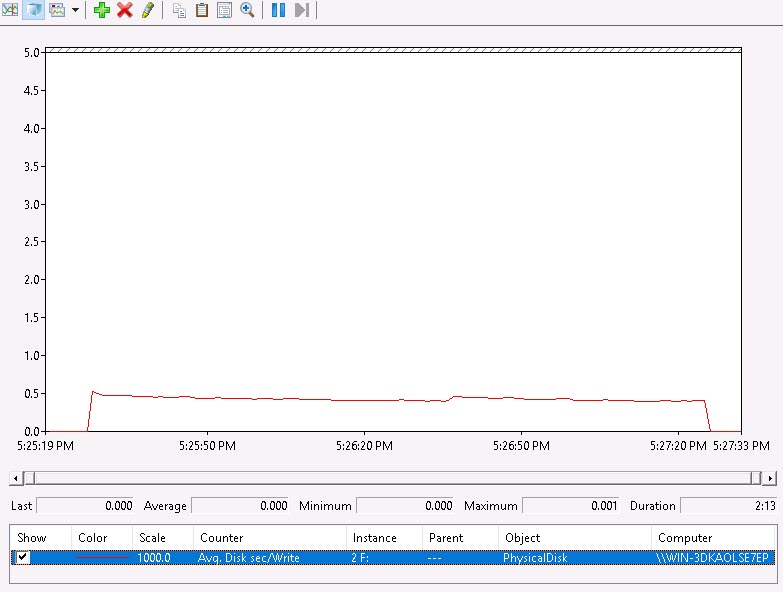
Now for a thin VMDK:
What you’d expect. The latency starts off at 1.5 ms which is due to the new writes to unallocated portions of the VMDK. As those segments get written to, the workload becomes more likely to write to a previously allocated block, so the average latency for these writes drop and drop until finally the whole VMDK is allocated and there are no more latency hits and it settles down to .5 ms.
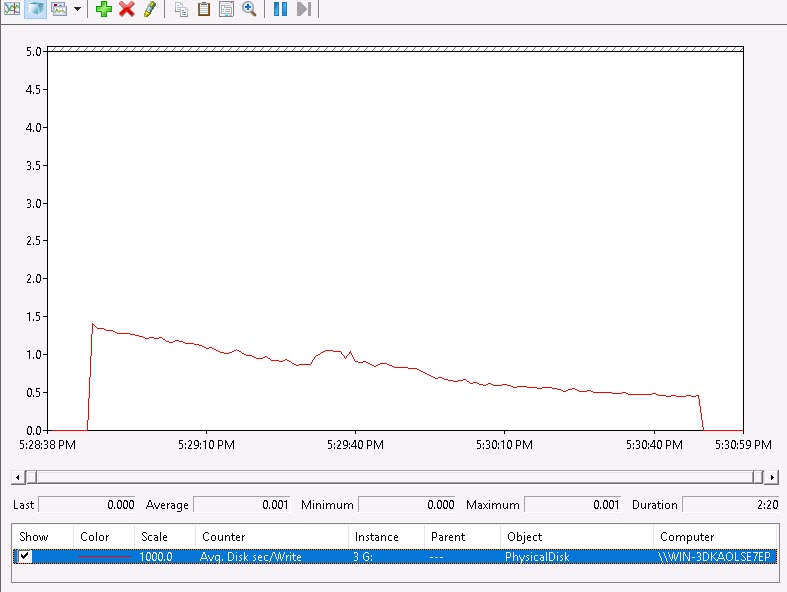
Now for the thin VVol:
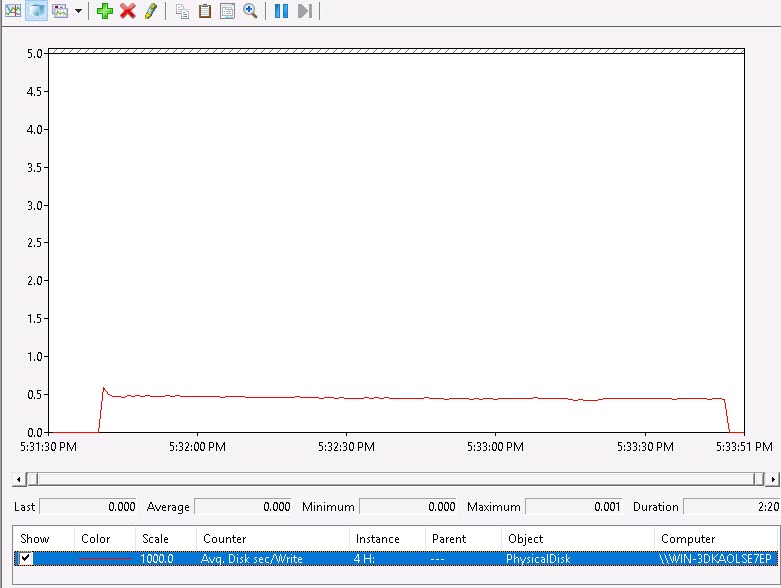
Beautiful! .5 ms throughout! So this proves out that with thin VVols, ESXi does not get in the way of the I/Os. No zeroing/WRITE SAME, so it is truly up to the array to deal with.
So it is worth mentioning, there is a concept of a thick VVol. Arrays can support both or just one of them.
And it is really up to the array on how it manages those types. So there may or may not be a performance difference with your array between thick and thin VVols. The example here is with the FlashArray. So certainly refer to your vendors documentation for their details. The point is though, any performance difference is not due to anything VMware does–the nice thing about VVols–they let the array do what it thinks is best when it comes to the I/O. So you can get all of the benefits as shown here without the performance overhead.
Nice Job, Cody, to demonstrate the difference among of them.