
Just recently, Rubrik announced their integration with the FlashArray to help backup virtual machines and avoid the common performance penalty incurred during VMware snapshot consolidation. See their announcement here.
First off, the problem. When you take a VM snapshot of a VMFS-based VM, there is a performance penalty. This is due to the fact that when a snapshot is “created” what really happens is that a delta VMDK is instantiated. All new writes from that virtual machine go to the delta virtual disks, instead of the base VMDK. This makes that base VMDK store the point-in-time state of the virtual disk. This process is referred to as “redirect-on-write”.
Here is a good KB for more detail:
Understanding VM snapshots in ESXi / ESX (1015180)
It is well understood that keeping these snapshots around is not a good idea-mainly due to the performance impact of this redirection. Basically, the rule is to not keep them for more than 24 hours, but really don’t keep them around longer than you have to. If something is about to happen (like a patch), take the VMware snapshot, install the patch, ensure nothing is broken, then remove the snapshot.
There are three primary performance-impacting events here:
- Creation of the snapshot. This is short, but is actually the worst hit, as it actually pauses all I/O (if that option is chosen to quiesce the state).
- Existence of the snapshot. Here is where the redirection happens and all workload is impacted during this period. This is experienced as higher latency.
- Deletion of the snapshot. A snapshot is not just deleted. It is merged back into the original VMDK, so this merge process can be quite impactful, especially if there are a lot of changes to merge.
Let’s look at an example.
I kicked off a light workload in my VM using VDBench:

Doing 2,000 IOPS, 70% write, 4KB I/O size. Nothing crazy, but to elucidate the concept.
The latency is looking pretty good, all sub-ms as it should be. .3 for reads and .4 for writes. Now I take a snapshot:
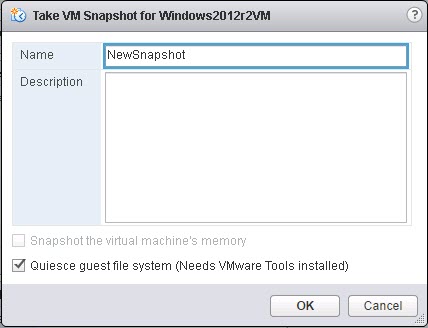
Immediately during the snapshot creation we see a big performance impact, but just briefly, as things are quiesced:
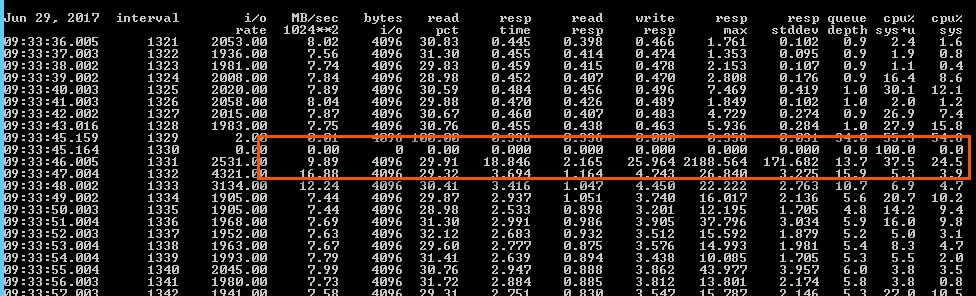
But moving forward, you can see the performance continues to suffer, as the latency is much higher than what it was without the VMware snapshot. Read response time is around 1 ms and write latency is 3 to even 5 ms or more. This latency is being introduced in the ESXi storage stack (the snapshots), as the FlashArray has no idea about the additional latency–it still reports as fine, but the throughput and IOPS goes way up due to the additional work being done with the snapshot:
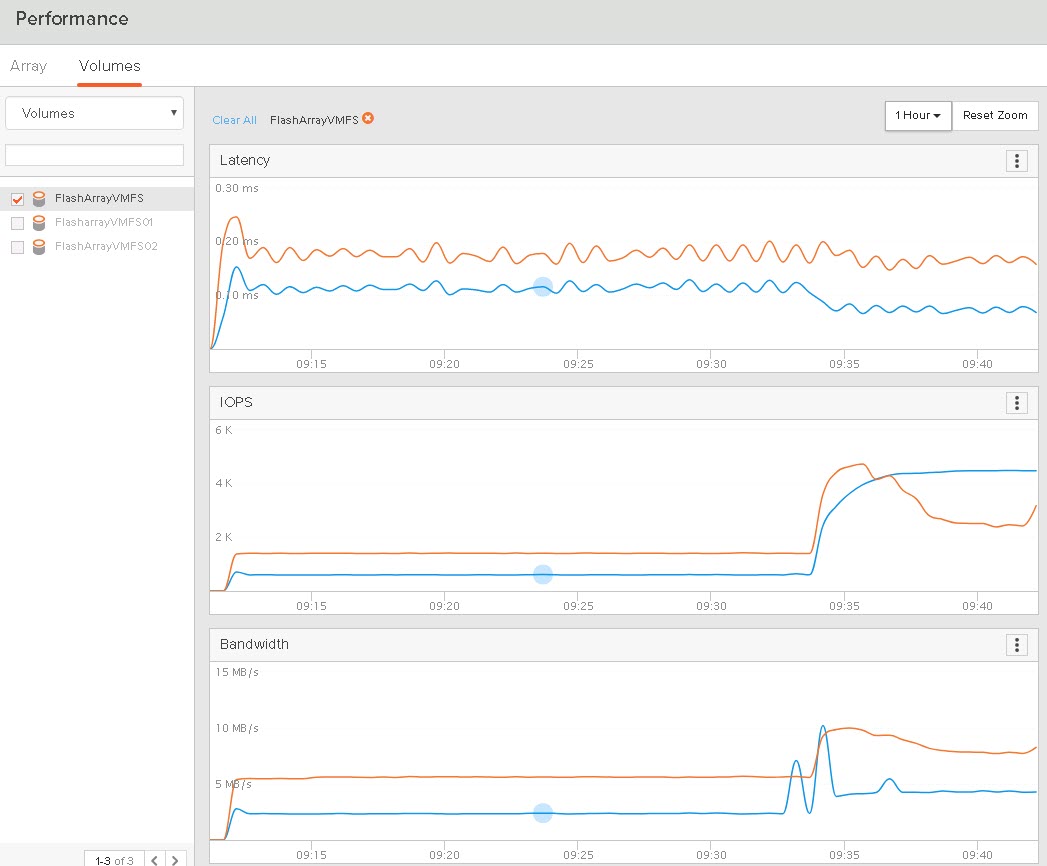
So the VM experiences quite the penalty when this snapshot is present.
Non-offloaded Backup
So back to Rubrik. I ran a normal backup on this VM (running the same workload as above) and at a high level this is what it does:
-
Queued manual backup of ‘Windows2012r2VM’ 7/01 7:23 am
Started manual backup of Virtual Machine ‘Windows2012r2VM’ 7/01 7:23 am -
Created vSphere snapshot snapshot-42 in 1 seconds 7/01 7:23 am
-
Taking a full backup of disk ‘[FlashArrayVMFS] Windows2012r2VM/Windows2012r2VM.vmdk’ from virtual machine ‘Windows2012r2VM’ because base disk is not found. This is expected for the first backup that includes this disk7/01 7:23 am
-
Ingested 2 TB of data 7/01 6:28 pm
-
Removed vSphere snapshot snapshot-42 in 5224 seconds 7/01 7:55 pm
-
Copied data for backup of ‘Windows2012r2VM’ to disk 7/01 7:58 pm
-
Completed manual backup of Virtual Machine ‘Windows2012r2VM’ 7/01 7:58 pm
Two things to note here:
The VMware snapshot was created at 7:23 AM, and the backup was complete at 6:28 pm which is when it started to delete the snapshot.
Which means:
The backup took ~11 hours.
Which means…
The VMware snapshot was around for ~11 hours.
Which means…
The VM workload was impacted (high latency) for ~11 hours. Not fun. ?
NOTE: I will note this example is a full backup, so subsequent incremental snapshots will very likely have a decreased backup duration, but this time still can be significant if the VM has a high change rate in between scheduled backups.
The VM snapshot delete took time too (87 minutes), and this is somewhat unavoidable. But the bulk of the time was the backup (665 minutes) and this is what the integration seeks to shorten, which has the biggest impact. That being said, the reduction of the snapshot lifetime should also in turn shorten the snapshot delete operation.
So what does Rubrik do?
The Rubrik FlashArray Integration
The goal here is to minimize the impact from a performance perspective to the VM targeted for backup. The most obvious way to do this is to reduce the duration that the VMware snapshot exists.
 For those Rick and Morty fans out there…
For those Rick and Morty fans out there…
So what Rubrik does is leverage the FlashArray snapshot technology to offload the backup process from the source production VM to one recovered from a snapshot. The process is like so:
- Identify the Pure Storage volumes hosting a VM
- Take a VMware snapshot of the VM
- Take a FlashArray snapshot of the volumes hosting the VM (yes it supports multiple VMFS volumes per VM)
- Delete the VMware snapshot
- Copy the FlashArray snapshot to a new volume
- Present it to a ESXi host, resignature and mount it
- Register the VM to the host and initiate the backup from the copied VM
- When complete, unregister the copied VM, unmount and destroy the FlashArray volume and snapshot
The benefit here is that unlike in the original process where the VMware snapshot exists for 11 hours, it only exists for seconds. Really reducing the impact duration on the VM.
Furthermore, it is important to note that the FlashArray snapshots are:
- Zero-performance impacting. They are not copy-on-write, they are not redirect-on-write. They are simply metadata preservations of the point-in-time of the volume. No data is moved or redirected. So no performance is hurt when a FlashArray snapshot is created, in existence, or deleted.
- Immediately created. It doesn’t take more than a few ms to create a FlashArray snapshot, regardless of size. So there is no waiting on one to be created.
- 100% data reduced. There is no capacity impact on the FlashArray when creating a snapshot. As data changes on the array, the snapshot might start to have some unique data stored by it, but since data is globally reduced it is unlikely to be a large amount, especially since it is temporary.
Setup
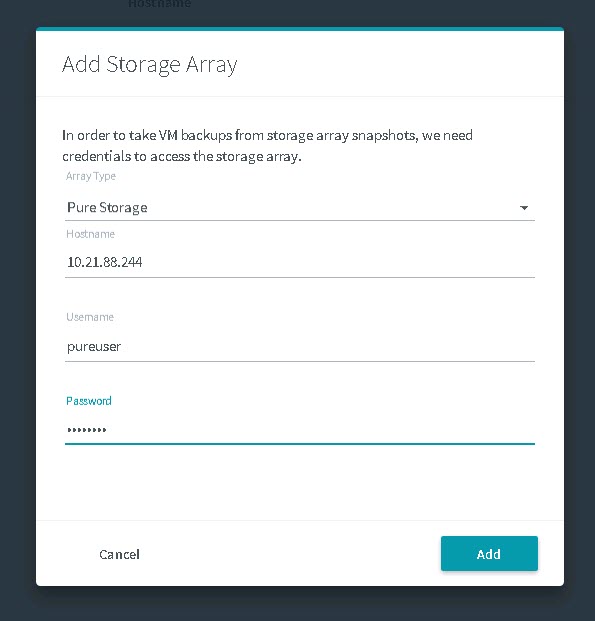
Setup is pretty easy. Go into you Rubrik interface and first add your FlashArray. You just need your IP/FQDN and username/password.
Then add your array:
Next, find your VM in the interface (mine is called Windows2012R2):
Then enable array integration for that VM:
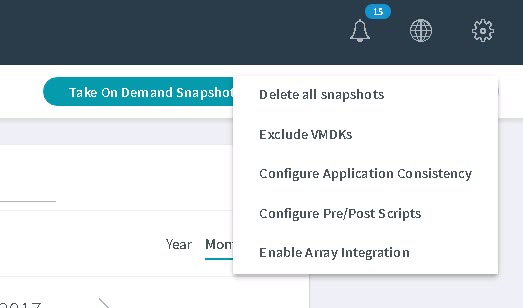
If you do not see the “Enable Array Integration” option, make sure you added the right FlashArray. Also, find your vCenter in the Rubrik interface and choose “refresh”. That did the trick for me.
And that is it! Pretty simple. So from now on, any on-demand or scheduled backups will use the array to offload the process. Very simple!
So I will kick off an on-demand full backup (no backups previously exist). The process timing looks like so:
- Queued manual backup of ‘Windows2012r2VM’ 6/30 8:04 am
- Started manual backup of Virtual Machine ‘Windows2012r2VM’ 6/30 8:04 am
- Created vSphere snapshot snapshot-38 in 1 seconds 6/30 8:04 am
- Taking a full backup of disk ‘[FlashArrayVMFS] Windows2012r2VM/Windows2012r2VM.vmdk’ from virtual machine ‘Windows2012r2VM’ because base disk is not found. This is expected for the first backup that includes this disk 6/30 8:04 am
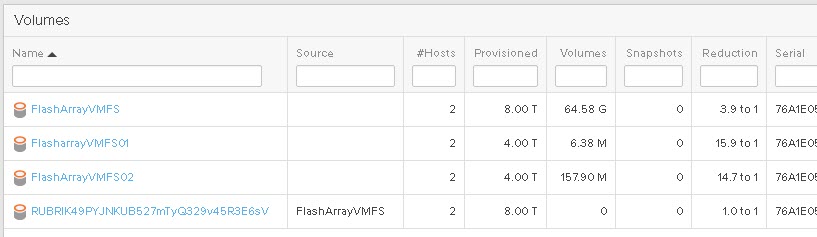
- Created storage array volume snaphot(s) 6/30 8:05 am

- Removed vSphere snapshot snapshot-38 in 2618 seconds 6/30 8:49 am

-
Mounted storage array volume snaphot(s) as vSphere datastore(s) 6/30 8:49 am
-
Created proxy vm ‘RUBRIK-HvZ1K-Ea8VQ-Windows2012r2VM’ to fetch data from storage array snapshot(s) 6/30 8:49 am
- Ingested 2 TB of data 6/30 7:43 pm
- Removed proxy vm ‘RUBRIK-HvZ1K-Ea8VQ-Windows2012r2VM’ 6/30 7:43 pm
- Unmounted vSphere datastore(s) of storage array volume snaphot(s) 6/30 7:43 pm
- Removed storage array volume snaphot(s) 6/30 7:43 pm
- Copied data for backup of ‘Windows2012r2VM’ to disk 6/30 7:47 pm
- Completed manual backup of Virtual Machine ‘Windows2012r2VM’ 6/30 7:47 pm

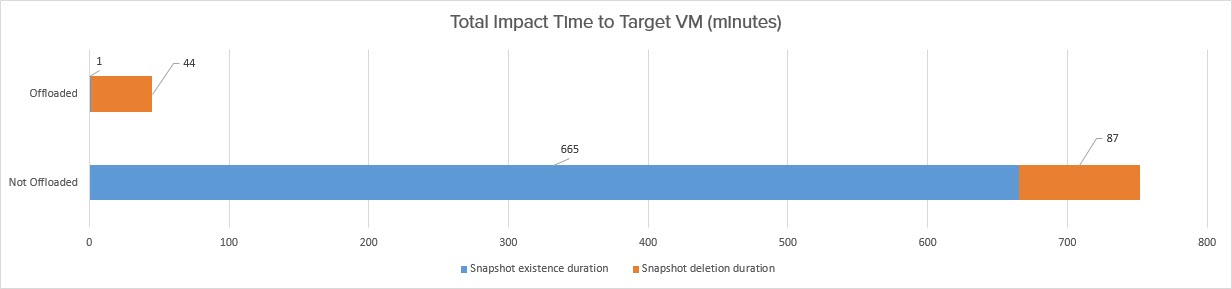
So a couple things to note here. First off the overall backup time is pretty much the same. This is expected. What is different is how long the VMware snapshot exists on the source VM. The VMware snapshot is created at 8:04 AM and then the deletion starts less than a minute later. So the “existence” of the VMware snapshot is down from 665 minutes to less than 1.
The deletion itself completes 44 minutes later at 8:49. So the deletion time is reduced as well, from 87 minutes to 44.
So the total impact time to the VM being backed up is reduced from 752 minutes (12.5 hrs) to 45 minutes. Not bad at all!
For a quick overview, check out this video I did with my good friend Nitin Nagpal (Director of Product Management at Rubrik):
Cody, great write up as always.
This looks incredibly promising. VMware snapshots and backups have been a challenge for high change rate VM’s
Does this process scale if there 20 VM’s to back on the same data store? Or does it run serially doing each VM snap / backup before moving to the next.
Also are individual file or VM recovery still possible?
All and all very exciting capabilities;
-sean
Thanks Sean! Hope all is well! Individual file/VM recovery is definitely still possible, the array snapshot is just used to offload, but the actually recovery used the standard process that Rubrik uses, so nothing is lost in this process from a functionality standpoint. As far as your first question, I am actually not entirely sure! Let me look and get back to you–it is a good question
So the answer is that the backups will run at the same time, but each VM will have its own copy of the datastore during the backup. Due to dedupe on the FlashArray this isn’t a huge deal from a capacity standpoint, but I could see some benefit from temporary datastore sharing. I passed your comment on to Rubrik!
I just tested this with vVols, and array based integration is not available for a VM on vVols. Do you know if Rubrik/Pure has plans to support this? I plan to reach out to my Rubrik team as well.
The array integration with VVols will not work, but really shouldn’t be needed either. I still have a lot of testing to do around VVols and backup–still a lot of opportunity here for additional value-add. As to when they will add features around VVols I do not know, but the need to offload is lessened in this case due to the snapshot process (hardware vs software) is different. Certainly stay tuned on this front
Hey Cody,
We are having pretty major issues with our spangly new Pure/Rubrik backup combo. When we are running backups we are hitting the 5000 VVOL limit on the Pure array (a combo of active volumes and destroyed volumes), which then causes major issues. Would you advise we use VVols or should be move back to VMFS?
Also we can’t get an answer if as part of normal backup operations should there be an eradicate issued on the recently destroyed volumes….?
Any light you can shed would be great.
Thanks,
RJ
Sorry I’m out of office last week and this week for my honeymoon so likely this was brought to me internally but I’m not checking email until I return. We are working on scale improvements right now so most of the issues around that should go away this year, so moving entirely off VVols probably isn’t the right answer, most customers I have seen (who are in similar scale limits) do some level of hybrid until we get some scale improvements. VVols for the VMs that really can benefit the most from them.
The only time we eradicate objects immediately is the swap and certain snapshots we take for CBT differentials, but standard managed snapshots (that manifest as volumes) are not eradicated because there is a chance they might need to be recovered.
I have been thinking about VVols and backup strategies lately and I think VVols might change how this is managed. When I get back we should have a chat. Please ask you account team to set something up.
Many thanks for sharing this quality article! I had a question please, I’m new to these technos, what are the prerequisites to observe to be able to benefit from this technological integration ? An opening of network flow between rubrik management and Pure FlashArray management? And maybe also the PureStorage plugin on the vCenter? Other prerequisites? Especially in terms of SAN/Network connectivity ?