
Having a best practices conversation the other day with a customer and the usual topic came up about any recommendations when it comes to virtual disk type. We had the usual conversation thin or thick, the ins and outs of those two. In the end it doesn’t matter too much, especially with some recent improvements in ESXi 6.0. The further question came up, well what about between zeroedthick and eagerzeroedthick? My initial reaction was that it doesn’t matter for the most part. But we had just had a conversation about Space Reclamation (UNMAP) and I realized, actually, I did have a big preference and it was EZT. Let me explain why.
First, let’s review the three main types of virtual disks:
- EagerZeroedThick–consumes all of the provisioned space upon creation of that virtual disk on the VMFS and fully zeroes out the underlying physical storage that is encompasses.
- ZeroedThick–consumes all of the provisioned space upon creation of that virtual disk on the VMFS but only zeroes out space as the guest needs it. Sometimes referred to as lazy zero or sparse.
- Thin–consumes space on the VMFS and underlying physical storage as the guest writes to it.
Okay, table that thought for a second.
Space Reclamation is an important part of maintaining your data-reduction all-flash-array, regardless of vendor in my opinion. When you delete a VM (or move one) that space is “dead” on the physical storage because it is only released by the filesystem, the underlying storage is not told. To release dead storage you either:
- Overwrite it
- Delete the physical volume
- Tell the storage to release the dead space specifically (UNMAP)
So the best idea is to run UNMAP as soon as a VMDK (or VM) is deleted or moved, but this isn’t really practical, because it is a CLI operation that must be manually kicked off or scripted. Especially if deleting VMs is a very common task (dev environments for instance) this is unlikely to happen. Most run it as a scheduled task once a week or whatever.
So let’s look at this scenario:
- I have a vmdk on a datastore and it consumes 100 GB on the VMFS and is fully written to by a guest, so 100 GB of non-zero data, not just simply allocated or a bunch of zeroes.
- I delete the vmdk so that the space is now free on the VMFS, but not on the physical device
- I now deploy a new 100 GB vmdk using the ZeroedThick allocation method. This reserves 100 GB of the VMFS but does not write anything down other than some meta data.
Nothing wrong with this process of course, it is a fairly common situation. So what does this have to do with space reclamation? Well, VMFS UNMAP only reclaims space that is seen as free by the VMFS filesystem. So in this case, in order to reclaim that space, we would have had to run UNMAP between step 2 and step 3. Since we instead just immediately deployed a new vmdk on the VMFS it is highly likely that the same logical space that was previously used is re-used by the new vmdk. VMFS has a very good re-use mechanism and will re-use space as much as it can when freed (a behavior which is meant to reduce dead space ironically).
So in this scenario, since zeroedthick is used, that space is not overwritten (the guest has written anything yet) but it is now reserved by the vmdk file, so VMFS UNMAP cannot touch it. VMFS reclamation will not reclaim that 100 GB of space from before.
At this point, the only way to reclaim the space is to overwrite it in the guest by zeroes (or of course overwrite it with real data that is actually needed). ESXi will only zero out that space as demanded by the guest OS as it needs it. So the guest sees it as free, but the VMFS sees it as reserves, but the physical device sees it as fully written to.
This can be very confusing to troubleshoot because the new owner of this VMFS will swear they wrote nothing to that new vmdk and they are indeed correct, but it is just stranded data from some previous vmdk that occupied that same space.
Let’s look at an example.
I have a Windows VM that has a 100 GB NTFS on a 100 GB vmdk. I have written a 83 GB file to it using VDBench with random data.
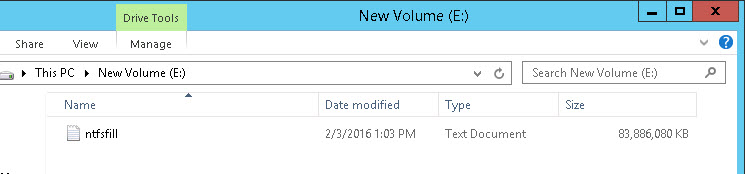
The vmdk is zeroed thick so it is 100 GB in size even though the guest has only written 83 GB. Like we spoke about, this is how zeroedthick works.
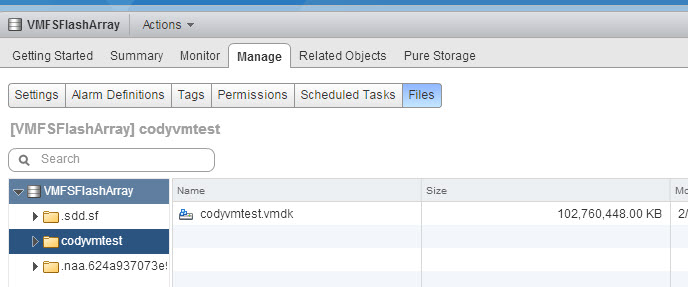
The VMFS has 100 GB used–the 100 GB of that vmdk.
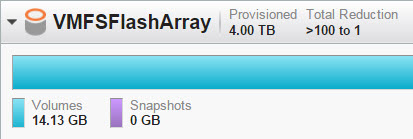
When looking at the FlashArray we can see that it takes about 14 GB of physical space after data reduction.
Great, so let’s delete the vmdk.
The VMFS now is empty:
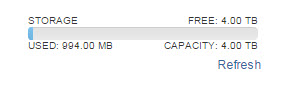
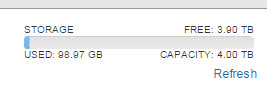
The FlashArray still reserves the space, so this 14 GB is still “dead”:
Now I create a new vmdk on that same datastore and add it back to my Windows VM as a quick-formatted NTFS.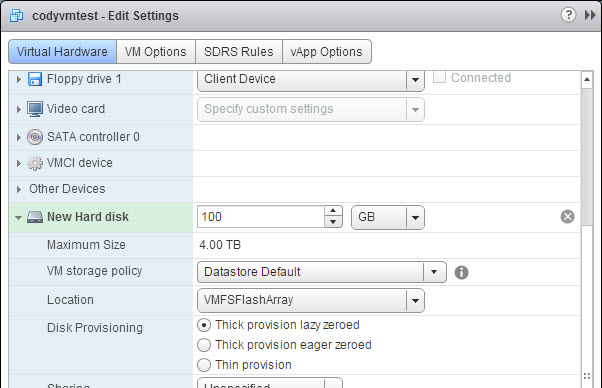
The FlashArray is still reporting 14 GB as used, even though there is no data written to the VMFS as far as the guest is concerned. If I run UNMAP, no space is reclaimed: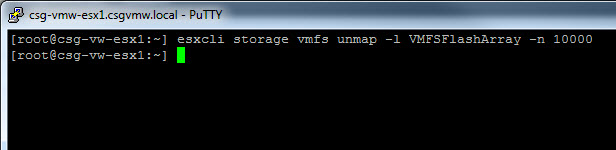
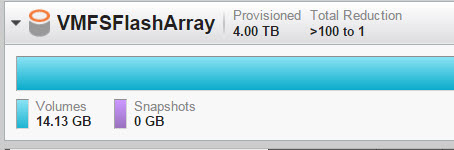
The previously used space is now totally stranded by the new zeroedthick virtual disk. The only way to reclaim is to zero it out in guest, which many VMware admins may not have access to. Or move it somewhere else and run UNMAP again.
So why does eagerzeroedthick help?
Well, like I said before, when you create a new eagerzeroedthick virtual disk it first fully zeroes it out before it can be used (using VAAI WRITE SAME). When the FlashArray receives zeroes it will not store them on the SSDs. It instead removes them inline and will return zeroes if those LBAs are read from. If those target addresses previously stored real data, those allocations will be removed on the SSDs (or metadata pointers depending if they are dedupe hits or not). So writing zeroes to written space is very much like running UNMAP–it effectively deallocates the space.
So deploying an eagerzeroedthick virtual disk will reclaim this old space by simply being deployed over it. Saves you the worry of having to reclaim it manually before with VMFS UNMAP or after with guest tools.
So if I delete the zeroedthick virtual disk I created and redeploy a new one in eagerzeroedthick form, the space will be reclaimed.
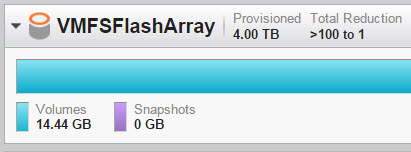
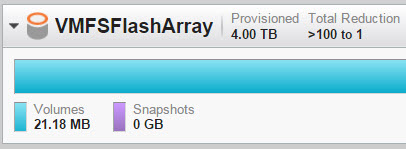
The FlashArray now reports 21 MB used. The eagerzeroedthick virtual disk deployment caused the dead space to deallocate as soon as that virtual disk was created.
It is possible that deleting and then deploying again will not re-use the same space, but it eventually will. So using a EZT type virtual disk will guarantee that this doesn’t happen.
Using EZT virtual disks and smart use of UNMAP will make your environment space efficient without much complexity.
The downside of EZT? Well it takes a bit longer to deploy new. That’s really about it. VAAI XCOPY time is pretty much the same. VMFS space efficiency is the same. EZT performance is a bit better (no zero-upon-new-write latency penalty).
In vSphere 6.0, I pretty much usually recommend thin virtual disks these days, and the use of thin makes most of this pointless. But if you want to go thick on a data reduction all-flash-array I would go eagerzeroedthick.
I am glad to see someone thinking the same on this topic. I’ve been proposing this for awhile as an alternative to using the SCSI UNMAP process and with zero detect there is no downside other than the creation overhead. I would much rather use the GUI (or PowerCLI) to create a EZT VMDK to fill up free space on a VMFS than to use the SCSI UNMAP command. Of course with vVol the reclaim at the VMFS level is no longer a problem. Good post!
Thanks! Agreed-the use of EZT can reduce or possibly eliminate the need for general UNMAP, and including in your everyday provisioning doesn’t take much effort, so why not?!