
Somewhat surprisingly I have been getting a fair amount of questions in the past few months concerning VMware vCenter Site Recovery Manager and Raw Device Mappings (RDMs) and using this with Pure Storage. Common question is whether or not we support this (we do) but more commonly it is about how it works. There is a bit of a misunderstanding on how they differ or do not differ from VMFS management in SRM. So figured I would put a post out to explain this. Old topic somewhat, but worth reviewing for those newer SRM customers. Plus, I haven’t found a whole lot of on-point posts anywhere, so why not?
Introduction
Let’s review the concept of RDMs and how they work with SRM. First Raw Device Mappings are exactly what they sound like, normal local or SAN devices that have been presented to ESXi and are not formatted with VMFS. Instead they are presented directly (bypassing the normal virtual SCSI layer of the ESXi kernel) to one or more virtual machines.
Please note this whole time I will be referring to Physical Mode RDMs, not Virtual Mode. Virtual Mode are so rare, it is not really worth getting into.
Anyways, RDMs are used for a few main reasons:
- VM admin (or application admin) wants to use array-based software to snapshot or replicate a database. Something like VSS etc. This is generally much harder to do on a granular and app-consistent basis with VMFS and virtual disks so RDMs are chosen.
- Legacy, migrated application where the data on the physical volume has simply not been migrated to VMDKs yet.
- The VM needs direct access to the array for other reasons, like in-band management, or to issue SCSI commands that ESXi would otherwise prevent.
Those are probably the most common use cases, probably missed a few, but you get the point.
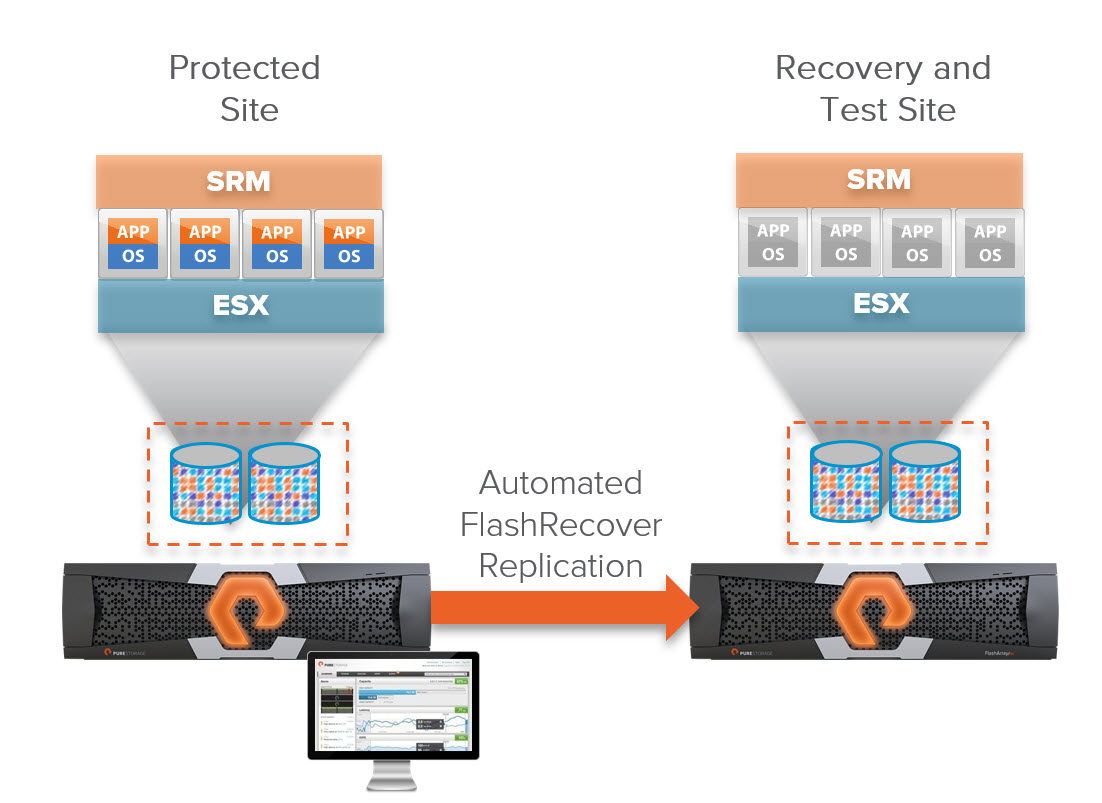
I’d say most commonly SRM is used to protect virtual machines that are solely using VMFS and virtual disks. In this situation the virtual disks are all sitting on one or more VMFS volumes that are protected with array-based replication (pRDMs are not supported with vSphere Replication last I checked).
In reality, SRM does not directly protect virtual machines though–it actually protects devices (LUNs, volumes, whatever you want to call them). For block storage (and the burgeoning VVol world notwithstanding) the present unit of storage granularity is the VMFS and therefore the underlying storage that hosts it. So when it comes to the Storage Replication Adapters in SRM, the difference in a RDM or a VMFS is zero.
The SRA tells SRM what volumes are replicated (the SRA has no idea if they are RDMs or VMFS) and then SRM sorts out that fact and also any VM relationships. When it comes time for SRM to failover VMs, SRM figures out what volumes they use, whether they be RDMs or VMFS and then tells the SRA I need you to failover volumes A, B and C. The SRA does not care nor know what VMs those host or how they host them.
Let’s take a look at a snippet of a XML printout in a SRA log file, this is the XML input SRM gives the SRA (in this case the Pure SRA).

All that is passed to the SRA is the information that the SRA originally sent in the device discovery process to uniquely identify a replicated volume (besides the serial number, the SRA doesn’t need that). Other than how they are named (I named the Pure volume that held the VMFS “SRMVMFS” and I named the RDM volumes “SRMRDM”), they aren’t identified differently or subsequently handled differently by the SRA.
How does SRM view RDMs?
SRM sees RDMs in a very similar way to a virtual disk. For instance, a virtual disk when it is a hard disk that belongs to a VM that is in a protection group, it is then related back to a VMFS. That VMFS must be replicated or an error is thrown. For an RDM, a RDM is seeing as a hard disk too when it belongs to a virtual machine. It must then be related back to a replicated device or an error is thrown. Just like a virtual disk, an RDM cannot be added to a SRM protection group directly–only VMFS volumes can. It must be added to a replicated VM and then it is automatically added to the SRM protection group (if it is replicated). If it is not replicated, or has not yet been identified by SRM as replicated, the associated VM(s) that use that RDM will be marked with an error.
How do i know if a RDM is replicated?
Let’s say you have an RDM that is added to a virtual machine and a VM in the protection group has an error like below:
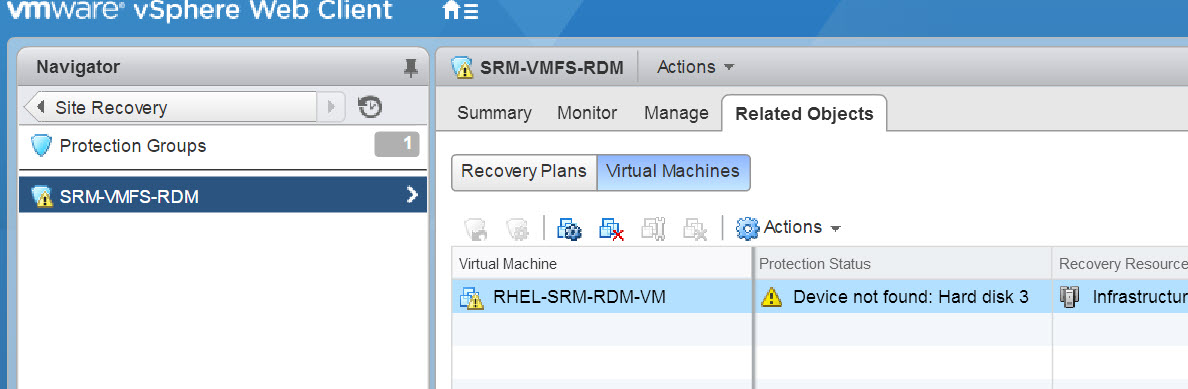
The VM is complaining because one of its devices, in this case a RDM is not replicated. This problem could be one of two things (most likely):
- The RDM is not replicated.
- The RDM is replicated but has not been discovered yet as replicated by SRM
So make sure it is replicated and/or run a device discovery operation in SRM with the appropriate array manager.
So the device will now appear in the list:
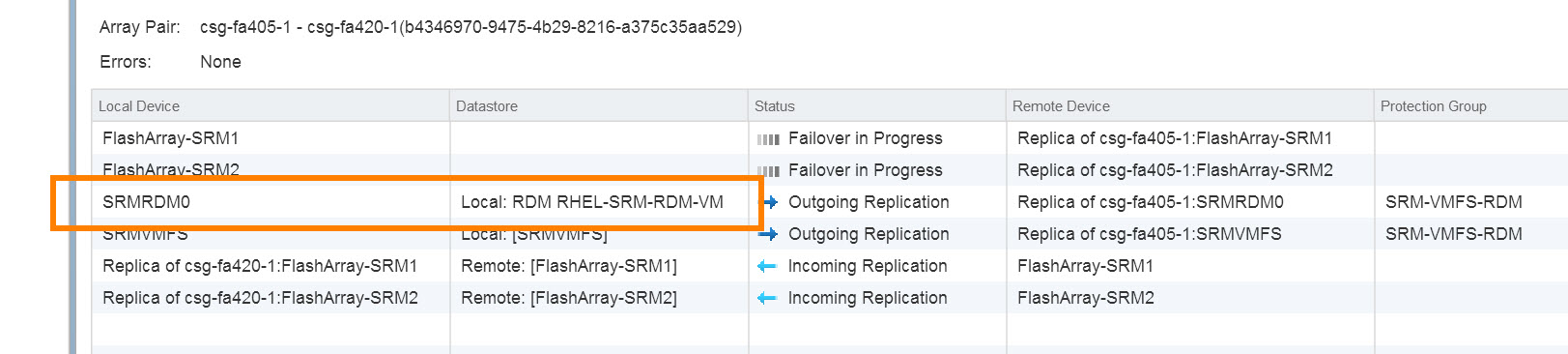
Note, RDMs are identified as such in here in the “Datastore” column. It will say “Local:” and then “RDM” and then the name of the VM that owns it.
The VM in the protection group will now be fully protected:
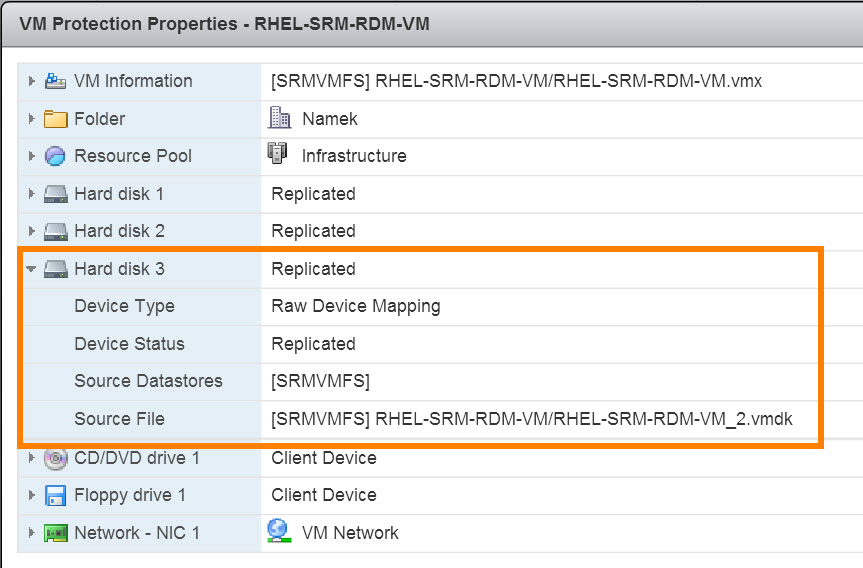
Let’s look at an example to explain this more fully.
Adding a RDM to an already protected VM
This first use case is as such:
- The virtual machine (its configuration files and various virtual disks) is entirely on replicated VMFS volumes
- The virtual machine is already protected by SRM (in a valid protection group).
- A non-replicated RDM has been added to the VM after step 1 & 2 are complete.
Presently, your PG will have an error like so:
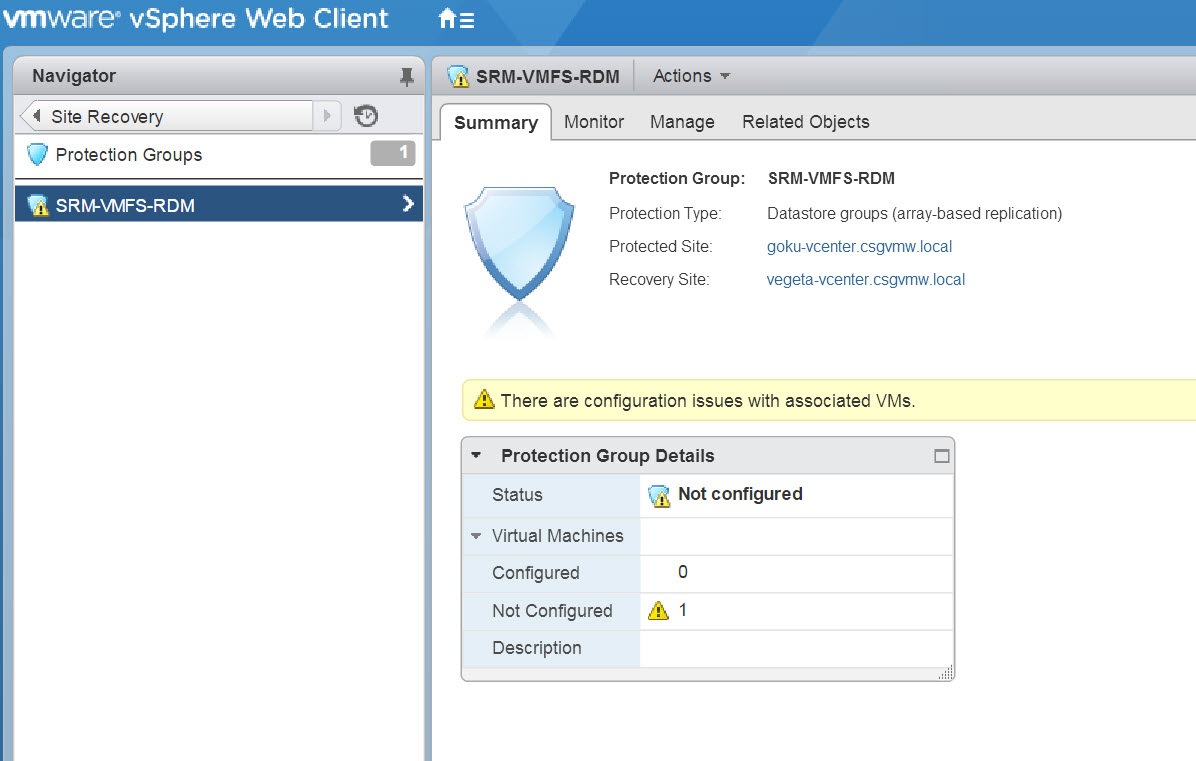
So at this point you must replicate the RDM. If you were using a virtual disk, you would have two options here:
- Move the virtual disk to a VMFS that is already known to be replicated. This move would achieve replicating the virtual disk and telling SRM that it is replicated (because SRM already knows that VMFS is replicated). So no further work would be needed.
- Identify the volume the virtual disk is on and then go to your array and establish replication on that volume hosting the VMFS. The you must discover it in SRM under a valid array pair. Plus you must re-run the “Edit Protection Group” wizard to add the VMFS to the SRM Protection Group. It is not automatically added.
For RDMs, you really only have option two. You must replicate that RDM and then discover its replication status in SRM as shown in the previous section.
As soon as it is discovered as replicated it will automatically be included in the “datastore group” by SRM. A “datastore group” is a grouping SRM uses to enforce virtual machine relationships. Like if a VM has a virtual disk on VMFS “A” and a different virtual disk on VMFS “B”, both VMFS “A” and “B” will be in the same datastore group and have to be added and removed to a protection group together.
As soon as that RDM is discovered by SRM as replicated it will be included in the datastore group and will be protected by the protection group that owns that datastore group immediately (UNLIKE a newly-replicated VMFS). Note it is listed below in the datastore group as a RDM and the VM name.
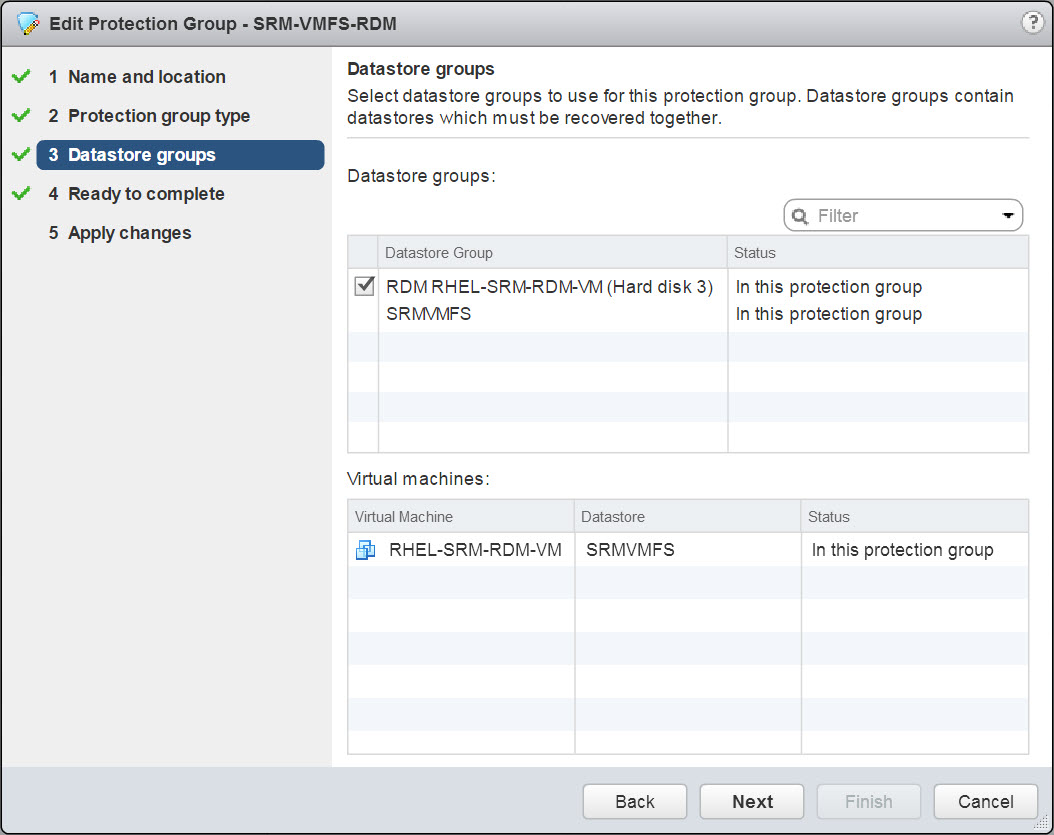
Conclusion
So in the end, in your head consider that SRM handles RDMs in a very similar fashion as virtual disks. Just make sure you have no errors in your protection group. If you do, check which VM is causing the error, then which virtual disk or RDM is the culprit and then identify the underlying volume and either replicate it, or make sure SRM knows it is now replicated by running a device discovery (note SRM runs automatic device discoveries every 24 hrs by default).
Final Thoughts on Pure Storage and RDMs
Just wanted to remind, we do absolutely support RDMs with our replication and within SRM. Just like VMFS. There are no special considerations in using our FlashArray replication with RDMs.
The only best practice we really have is that we highly recommend putting related volumes (whether they be RDMs or VMFS or both) in the same FlashArray Protection Group (yes we use the same name as SRM does, they are both called Protection Groups). FlashArray Protection Groups are consistency groups and all volumes in them are replicated in a write-consistent fashion–therefore it is wise to put volumes in use together in the same Protection Group so they are consistent with one another when failed over.
Hello I have same issue but unable to solve it. When we scan array pairs on SRM. we are able to see the replicated RDM. But still we are unable to protect vm
What is the error? Inability to protect a VM could be caused by a large variety of issues
Is there a video of this? How does SRM deal with the RDM being mapped to a LUN ID in the original location and then recovering it in the new location on the other array that doesn’t have the same LUN ID? What happens when you try and power up the VM?
The LUN ID shouldn’t matter to the VM, SRM (and ESXi) uses the serial number as the identifier so whatever LUN ID it uses for the RDM volume shouldn’t matter if it changes. For the in-guest side of things it uses the same SCSI slot for the VM so it won’t change from the guest OS side
Thank you, I am still confused. Can you tell me how does SRM manage associating the P-VOL to S-VOL mapping so that it knows what device to replace and what device to attach at the replication target side?